Chapter 2 Model Evaluation
![]()
2.1 Introduction
Validating and assessing the uncertainty of a model is just as, if not more important, than generating the model itself. Validation quantifies the model’s ability to explain variance in the data while uncertainty quantifies the confidence of model prediction. Uncertainty and validation assessments enable the end user to better understand model error, the nature and distribution of the input data, and the overall accuracy and spatial applicability of the model. Within a soil model, there are several sources of error:
- Measurement errors
- Interpretation errors
- Digitization errors
- Classification errors
- Generalization errors
- Interpolation errors
- Semantic errors
Errors are simply the difference between reality and our representation of reality. Assessing the data structure with simple statistical measures such as mean, median and mode can be useful for understanding the central tendency of the data, but more complicated calculations are needed to get at dispersion or the variation of a property within a population to further assess error and uncertainty (Zar, 1999).
Measure of Dispersion
- Range: The difference between the highest and lowest values measured or observed. Not always reliable because it can include outliers, error, or misclassified data.
- Quantiles: These refer to 25% increments in the rank of observations. Typically, the 25th and 75th quantiles are used to represent the spread of the most typical values around the central tendency.
Measure of Variation * Variance: The deviation of from the mean is calculated as sum of squares (SS) to use absolute deviation (eliminate any distinction between negative and positive correlation). \(variance (sample) = \frac{SS}{n-1}\)
- \(SS = \sum{(X - x)^2}\)
- Standard deviation: Used to return variance to the original units \(sd = \sqrt{\frac{SS}{n-1}}\)
- Coefficient of variation: Scale standard deviation with mean so that multiple properties can be compared \(CV = \frac{SD}{x}\)
Measures of Certainty
- Standard Error: represents the variance of the mean that would be found with repeated sampling. Estimated by dividing standard deviation by the square root of n. The concept of standard error is important for hypothesis testing.
- Confidence interval: Interval in which you are confident that a given percentage (known as the confidence limit 95, 80, 75%) of the population lie. If a normal distribution is assumed, for a 95% confidence interval, it can be estimated that the value is 95% likely to fall between as SD * 1.96 +/- mean.
2.1.1 Examples - Dispersion
Below is a simulated example demonstrating the affect of sample size and standard deviation on quantile estimates.
## # A tibble: 8 × 5
## # Groups: sd [2]
## sd n med_min med_mean med_max
## <chr> <fct> <dbl> <dbl> <dbl>
## 1 sd = 1 n = 10 6.09 7.09 7.77
## 2 sd = 1 n = 30 6.57 6.93 7.22
## 3 sd = 1 n = 60 6.73 7.09 7.38
## 4 sd = 1 n = 100 6.79 7.02 7.31
## 5 sd = 2 n = 10 5.53 6.96 8.03
## 6 sd = 2 n = 30 6.27 7.17 8.17
## 7 sd = 2 n = 60 6.40 6.98 7.51
## 8 sd = 2 n = 100 6.37 6.99 7.42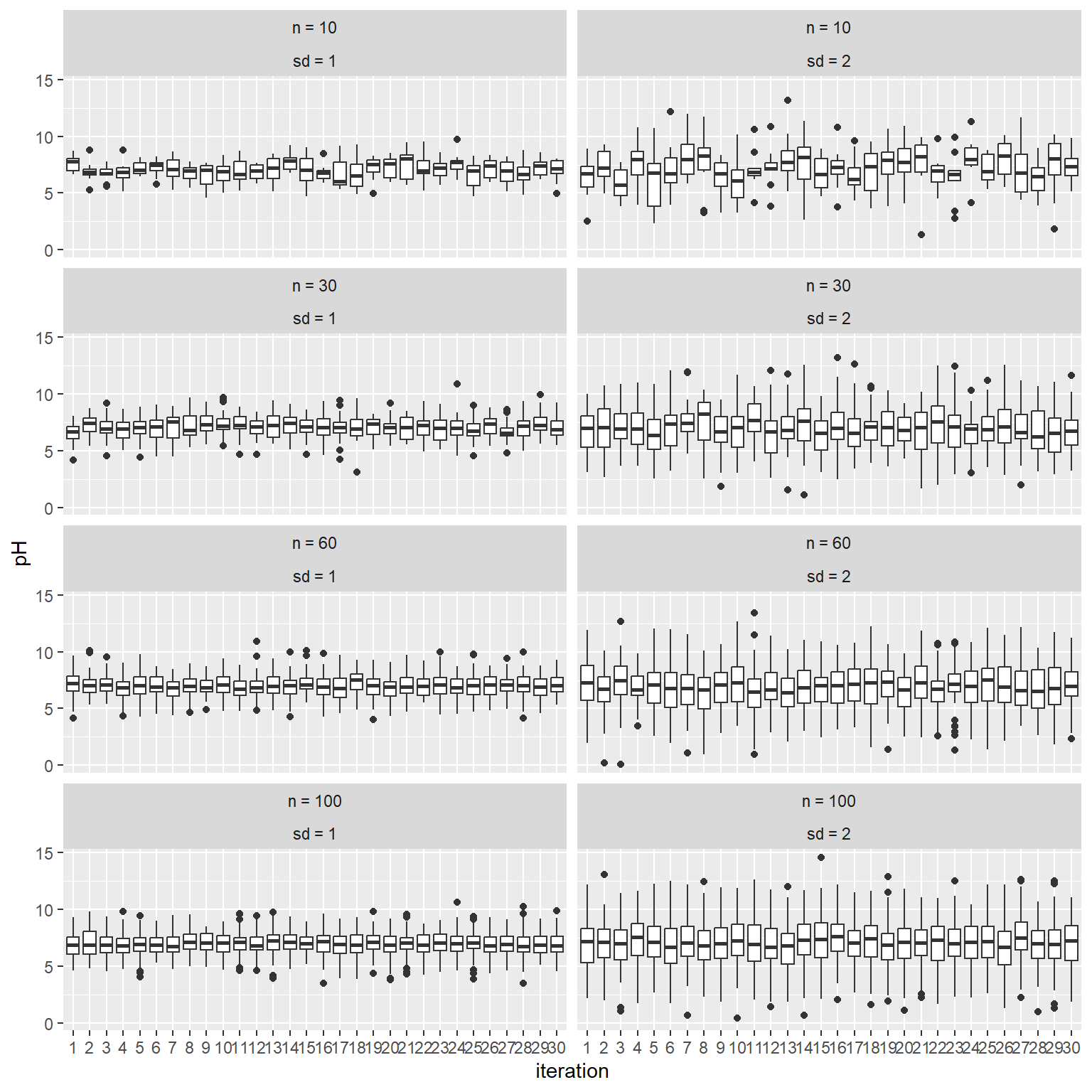
The results show that quantile estimates are more variable with smaller sample sizes and larger inherent standard deviations. This example demonstrates how our results would differ if we were to sample the same soils again. We would be “uncertain” of our results unless the underlying standard deviation is small or our sample size was large. Both factors would also impact how certain we could be that 2 or more classes of soils are different.
2.1.2 Examples - Variation and Certainty
Demonstration of how to calculate variance.
# calculate the mean
mu <- mean(test$pH)
# subtract mean from each value and square (i.e. residuals)
test$S <- (test$pH - mu)^2
# calculate overall sum of squares
SS <- sum(test$S)
# calculate standard deviation (length gives us the total number of sample/observations)
sqrt(SS / (length(test$pH) - 1))## [1] 1.586635Note below how our estimate of the variance can vary widely, particularly for simulated datasets with a inherent standard deviation of 2.
## # A tibble: 8 × 5
## # Groups: sd [2]
## sd n sd2_min sd2_mean sd2_max
## <chr> <fct> <dbl> <dbl> <dbl>
## 1 sd = 1 n = 10 0.578 0.917 1.28
## 2 sd = 1 n = 30 0.667 0.993 1.33
## 3 sd = 1 n = 60 0.782 1.00 1.16
## 4 sd = 1 n = 100 0.887 1.01 1.13
## 5 sd = 2 n = 10 0.934 1.91 2.76
## 6 sd = 2 n = 30 1.48 1.98 2.40
## 7 sd = 2 n = 60 1.37 2.00 2.41
## 8 sd = 2 n = 100 1.81 2.01 2.24Now let’s see Standard Error (standard deviation / square root of n) below. The results show how our estimates become more precise as the sample size increases.
## # A tibble: 8 × 5
## # Groups: sd [2]
## sd n SE_min SE_mean SE_max
## <chr> <fct> <dbl> <dbl> <dbl>
## 1 sd = 1 n = 10 0.183 0.290 0.406
## 2 sd = 1 n = 30 0.122 0.181 0.243
## 3 sd = 1 n = 60 0.101 0.129 0.149
## 4 sd = 1 n = 100 0.0887 0.101 0.113
## 5 sd = 2 n = 10 0.295 0.604 0.873
## 6 sd = 2 n = 30 0.270 0.361 0.439
## 7 sd = 2 n = 60 0.177 0.258 0.311
## 8 sd = 2 n = 100 0.181 0.201 0.2242.2 Theory of Uncertainty
At it’s most basic level, uncertainty is simply a lack of certainty. In soil survey, uncertainty encompasses both of these aspects:
- you’ve gathered multiple observations and you need to describe them in relation to one another, and
- you must predict a property or characteristic at unobserved locations.
It is difficult to quantify the knowledge we have about data and information uncertainty. While we may have good data of the accuracy of our GPS, how likely are we to include that in our estimates of model error? How important is it? In other disciplines, they spend a lot of time quantifying and tracking measurement error. In soil science, we tend to treat measurement as having an exact known location and value. Given the unknowns in mapping and predicting soil properties, this is a reasonable treatment of relatively small levels of error.
When using secondary information as data (or data that is actually a prior prediction or result of a model, including soil components), considering incorporated error can be crucial. One way to deal with this is through re-sampling an alternate way is to through error propagation theory. The most common way to deal with this in soil survey and digital soil mapping is to assess error through model validation.
Explanatory vs. Predictive Modelling
While explanatory and predictive modeling can use the same types of models, data and even questions, the errors and uncertainty are important for different reasons
Explanatory or Descriptive - data are collected and analyzed in order to test causal hypothesis and observe correlations and relationships between data element. Often used at the beginning phases of soil-landscape exploration. How does the soil relate to each of the soil forming factors?
Predictive - applying a model or algorithm to data for the purpose of making a prediction (in new or unknown locations) (Shueli, 2010).
2.3 Resampling to Estimate Uncertainty
When calculating many basic statistical parameters, the assumption is that the data is parametric. That implies that the data is continuous (ratio or interval) and normally distributed. This is rarely the case with soil data. Soil properties are often not normally distributed (you cannot have less that 0% organic matter, for instance) and often we are trying to predict soil taxa or other nominal classes.
Re-sampling is a general term that defines any procedure to repeatedly draw samples form a given data-set. You are essentially pretending to collect a series of separate samples from your sample set then calculating a statistic on that sample. Re-sampling techniques can be used on known and unknown data distributions for uncertainty estimation and validation (Good 2013).
2.3.1 Examples - Confidence Intervals
# this bootstrap is estimating the uncertainty associated with the variance of sas$pH_0.30_obs
# an example of getting a confidence interval through bootstrapping (no assumption of a normal distribution)
# load the GSP Salt Affected Soil dataset
url <- "https://raw.githubusercontent.com/ncss-tech/stats_for_soil_survey/master/data/gsp_sas.csv"
sas <- read.csv(url)
N <- nrow(sas)
# abbreviate our data to simply the commands
ph <- na.exclude(sas$pH_0.30_obs)
n <- 100
# set number of iterations
k <- 50
# create a data frame to store the results
boot_stats <- data.frame(
vars = numeric(k),
means = numeric(k)
)
# for each instance (i) in the set from 1 to N (50 in this case)
for (i in 1:k) {
# create a new variable dB from each bootstrap sample of d
boot.sample = sample(ph, n, replace = TRUE)
boot_stats$means[i] = mean(boot.sample)
boot_stats$vars[i] = var(boot.sample)
}
quantile(boot_stats$vars)## 0% 25% 50% 75% 100%
## 0.7541777 1.0309117 1.1386976 1.2139855 1.5424279
# Traditional Approach
ci <- c(
# lower 5th
l = mean(ph) - 1.96 * sd(ph) / sqrt(N),
# upper 95th
u = mean(ph) + 1.96 * sd(ph) / sqrt(N)
)
# Compare Bootstrap to Confidence Interval
quantile(boot_stats$means, c(0.025, 0.975))## 2.5% 97.5%
## 5.770794 6.205964## l u
## 6.002983 6.0243662.4 Performance Metrics
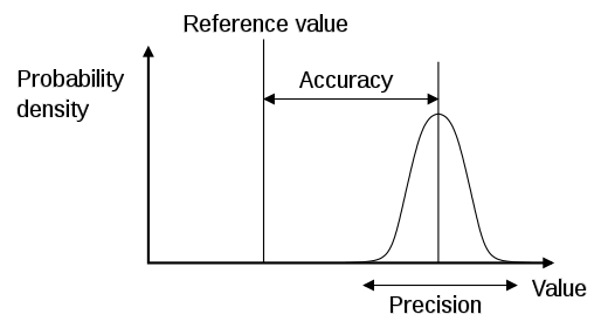
When evaluating a model, we need to estimate both it’s accuracy and precision. Accuracy estimates the ability of a measurement or prediction to match the actual or reference value of the quantity being measured. Precision in contrast estimates our ability to reproduce a measurement or prediction consistently. Typically people will refer to uncertainty, which is the inverse of precision.
Below is a summary of the various measures used to quantify accuracy and precision. The choice of metric depends on whether we are measuring or modeling continuous or categorical variables. In general, all models that estimate continuous variables are referred to as regression models. Sometimes regression models are referred too as quantitative, while categorical models are referred too as qualitative.
2.4.1 Regression Metrics
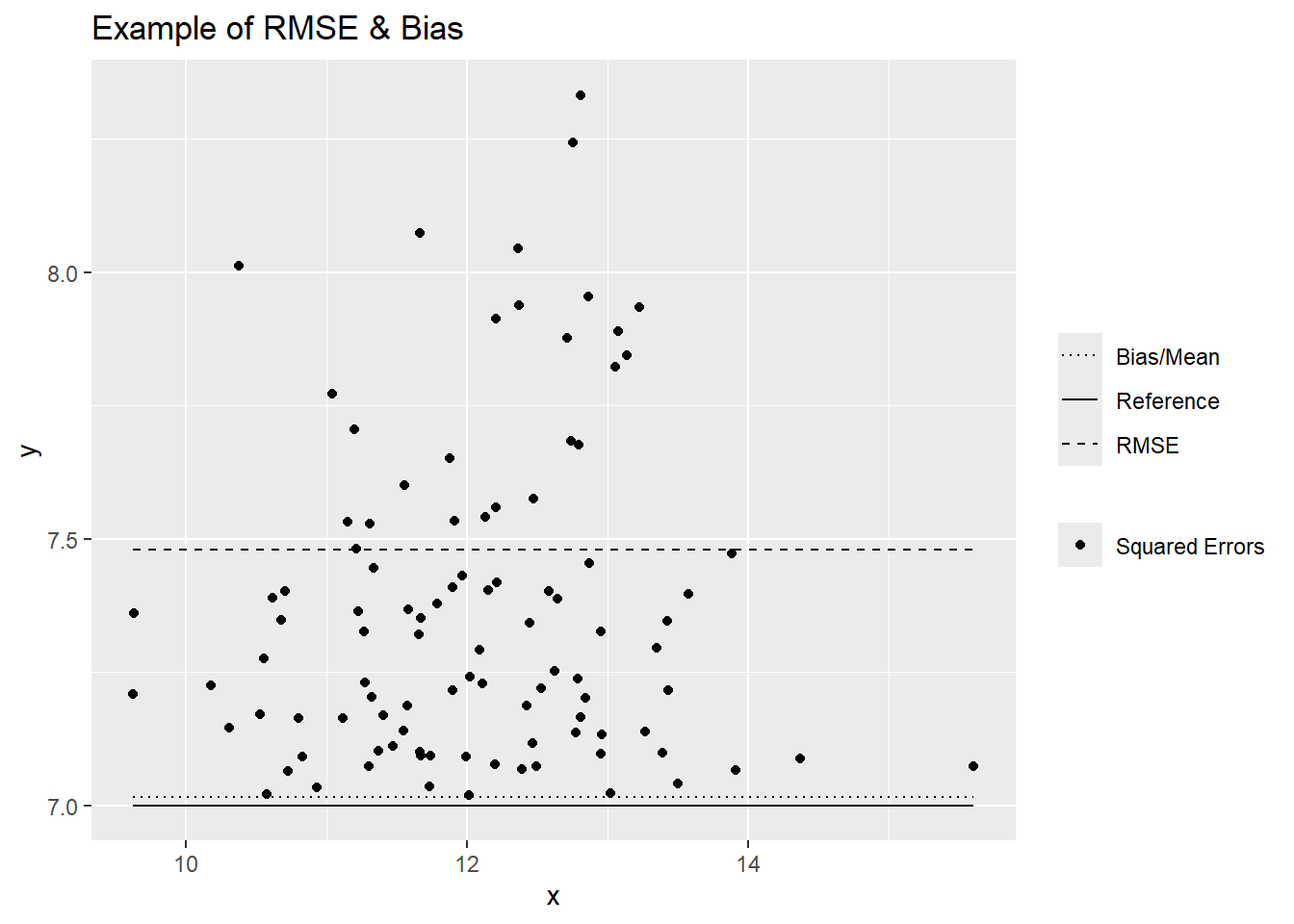
Bias:
- Mean Error (ME)/Prediction Error/Bias:
- Description: Quantifies whether the overall error is systematically positive or negative; the closer to 0, the better.
- Pro: In the same use as the original values
Accuracy:
- Mean Square Error (MSE):
- Description: Squared estimate of the average error size.
- Con: Not in the same units as the original values.
- Root Mean Square Error (RMSE):
- Description: Positive estimate of the average error size; the smaller, the better.
- Pro: In the same units as the original values.
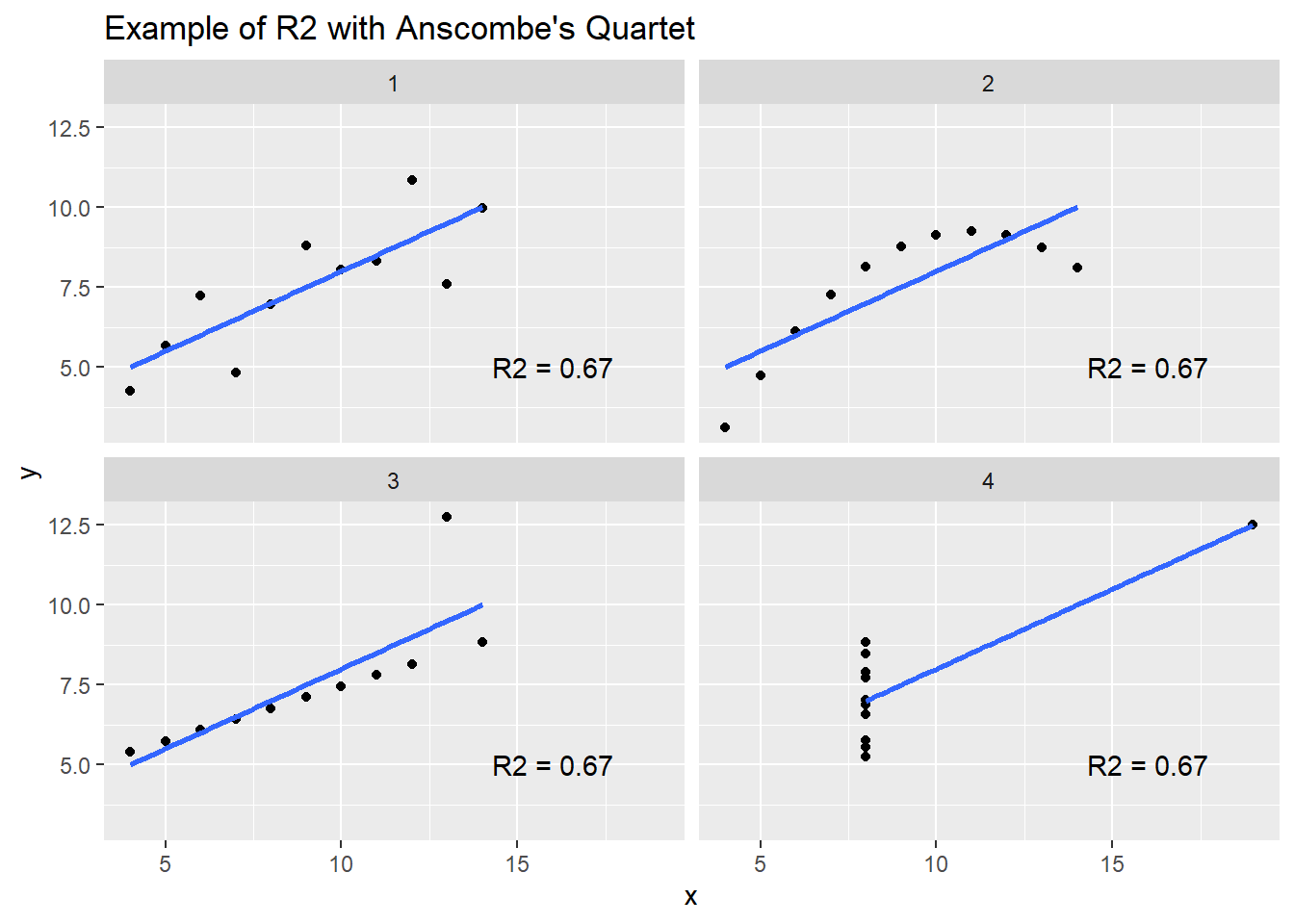
- Coefficient of Determination (R2):
- Description: Represents the proportion of variance explained by the model.
- Pro: Values range between 0 and 1. Values < 0 can occur if the prediction is worse than simply predicting the average value.
- Con: Over-optimistic when extreme values or skewed distributions are present. Often confused with the squared Pearson’s correlation coefficient (r2).
- References: Kutner et al. 2004; Zumel and Mount 2020
Precision/Uncertainty:
- Standard Error (SE):
- Description: Error in the model parameters (e.g., coefficients or overall prediction).
- Confidence Interval (CI):
- Description: Conversion of the SE to an interval according to a given probability (e.g., 95 percent); its range is narrower than the prediction interval.
- Con: Assumes a normal distribution, unless transformed or bootstrapped.
- References: Webster (2001)
- Prediction Interval (PI):
- Description: Interval designed to capture the range in values of a prediction according to a given probability.
- Relative Prediction Interval (RPI):
- Description: Ratio of the 95 percent prediction interval range to the 95 percent observed inter-quantile range in values. Can use different probability values (e.g., 90 percent PI to 90 percent inter-quantile range). Pro: Typically ranges between 0 and 1; values larger than 1 indicate very high model uncertainty. No distribution assumptions. References: Nauman and Duniway (2019)
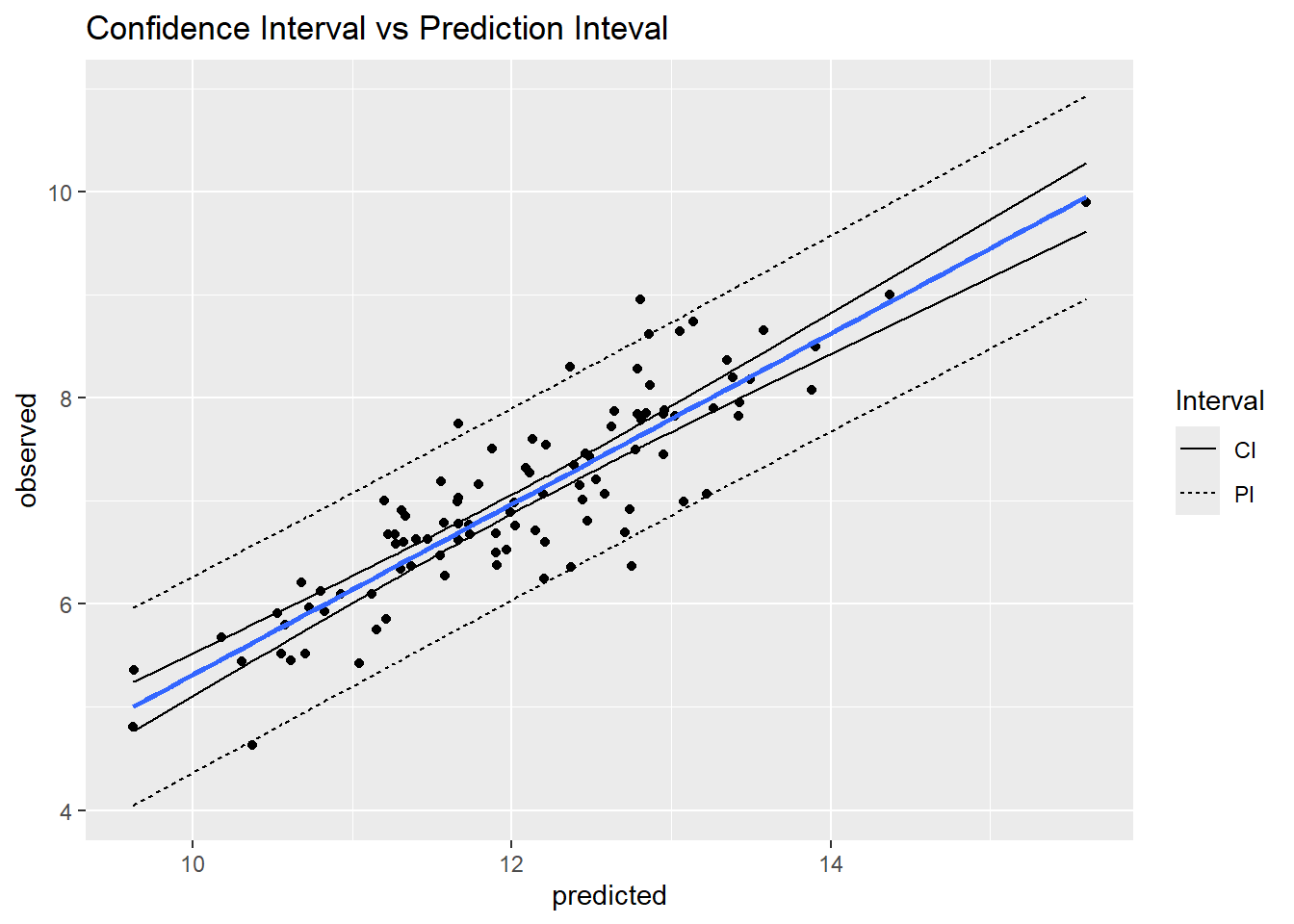
2.4.2 Examples
library(caret)
# Numeric accuracy metrics----
# R2 ----
caret::R2(
pred = sas$pH_0.30_pred,
obs = sas$pH_0.30_obs,
formula = "traditional",
na.rm = TRUE
)## [1] 0.8526782## [1] 0.4690274# Numeric precision/uncertainty metrics----
# R2 confidence interval
vars <- c("pH_0.30_pred", "pH_0.30_obs")
MBESS::ci.R2(
R2 = 0.85,
N = sum(complete.cases(sas[vars])),
K = 1,
conf.level = 0.975
) |>
unlist() |>
_[c(1, 3)]## Lower.Conf.Limit.R2 Upper.Conf.Limit.R2
## 0.8462365 0.8536713# RMSE confidence interval
## Standard Error
n <- sum(complete.cases(sas[vars]))
SE <- qnorm(0.975) * sqrt(var((sas$pH_0.30_obs - sas$pH_0.30_pred)^2, na.rm = TRUE) / n)
SE## [1] 0.00541306## [1] 0.4645869 0.4754131# plot errors
idx <- sample(1:nrow(sas), 100)
ggplot(sas[idx, ], aes(x = pH_0.30_pred, y = pH_0.30_obs)) +
geom_point() +
# draw a 1 to 1 line
geom_abline() +
# draw a linear fit; method = "lm"
geom_smooth(method = "lm")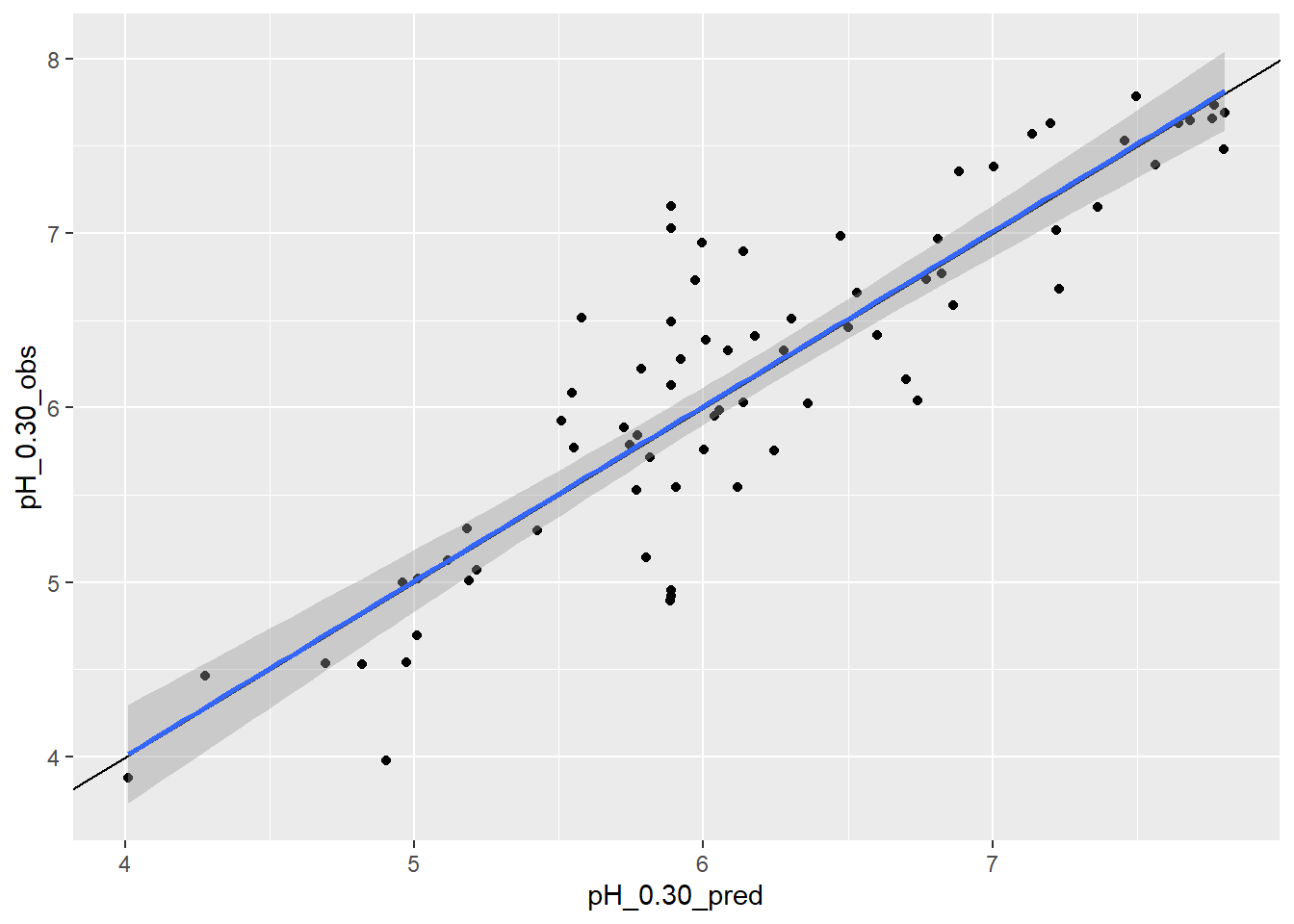
ggplot(sas, aes(x = pH_0.30_pred, y = pH_0.30_obs)) +
# use a hex geom if there are too many points and they overlap
geom_hex() +
geom_abline() +
geom_smooth()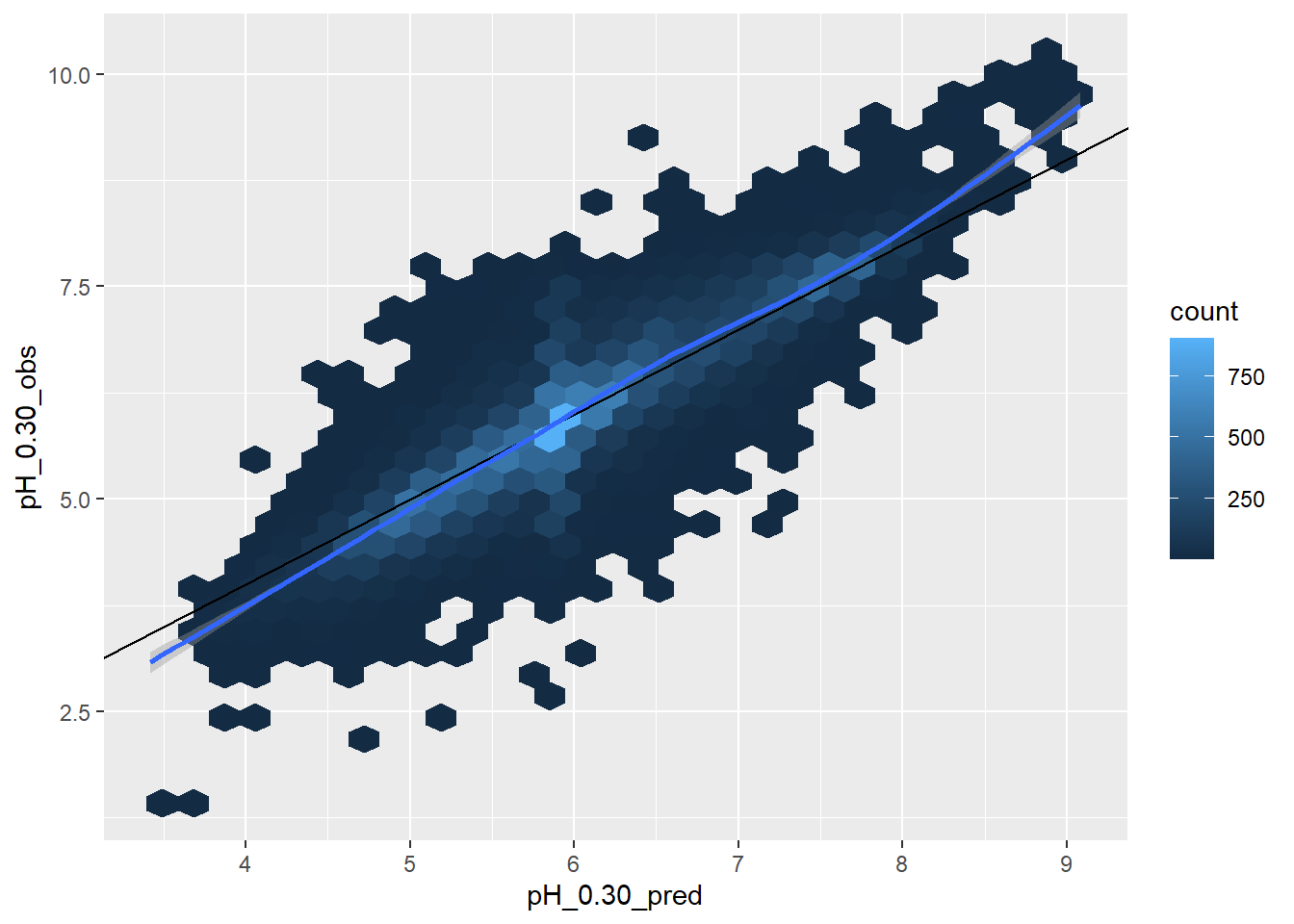
2.4.3 Exercise 2
Append the following exercises to your previous R script.
Compare the traditional \(R^2\) to the alternative \(R^2\) for
EC_0.30_obsvsEC_0.30_pred?Calculate the
RMSE()andMAE()forEC_0.30_obsvsEC_0.30_pred?Plot a hex bin scatterplot of
EC_0.30_obsvsEC_0.30_predwith a linear smoother.Forward you R script your instructor.
2.4.4 Categorical
2.4.4.1 Probability-based metrics (threshold-independent)
Beware the \(D^2\), Tjur’s D, and AUC (or c-statistic) only apply to binary classes.
Accuracy:
- Brier Score (BS):
- Description: In the case of binary outcomes (e.g., 1 vs. 0), it is equivalent to the Mean Square Error, where a positive outcome equals 1 minus the predicted probability. For multinomial outcomes, the squared error is averaged for all classes. Lower values denote higher accuracy.
- Pro: Integrates more information about predictions (all probabilities) vs. the most likely class used by overall accuracy or tau index.
- Con: Does not incorporate prior knowledge of class proportions. Does not incorporate class similarity.
- References: Brier (1950); Harrell (2015); Steyerberg (2019)
- Deviance Squared (D2) or Pseudo R2:
- Description: The proportion of deviance explained.
- Pro: Values range between 0 and 1. Values < 0 can occur if the prediction is worse than simply predicting the average value.
- Con: Over-optimistic when extreme values or skewed distributions are present.
- Coefficient of Discrimination (or Tjur’s D):
- Description: Difference in average probability of true positives and true negatives. It is another alternative version of D2 or Pseudo R2.
- Pro: Values range between 0 and 1.
- References: Tjur (2013)
- Concordance (c) Statistic or Area Under the Curve (AUC):
- Description: Probability that a binary classifier does better than random chance. The area under the receiver operator characteristic curve.
- Pro: Values range between 0.5 and 1.
- Con: Less sensitive than D2.
- References: Hand (2012); Harrell (2015)
Precision/Uncertainty:
- Shannon entropy:
- Description: Quantitative measure of “information,” “complexity,” “certainty,” or “diversity” contained within a vector of probabilities. Larger values denote less information, higher complexity, less certainty, and greater diversity.
- Pro: Integrates “confusion” over all probabilities. Entropy values from different models (e.g., differing numbers of classes) can be directly compared.
- Con: Does not incorporate the similarity between classes.
- References: Shannon (1948)
- Normalized Shannon Entropy:
- Description: An alternate version of Shannon Entropy that is constrained to the interval [0,1].
- Pro: Integrates “confusion” over all probabilities. Constrained to [0,1].
- Con: Cannot be used to compare models with differing numbers of classes. May not be implemented in all software packages.
- References: Kempen et al. (2009)
- Confusion Index:
- Description: An index of confusion among the top two most likely classes.
- Pro: Simple calculation and constrained to [0,1].
- Con: Cannot be used to compare models with differing numbers of classes. Only describes uncertainty of top two classes. May not be implemented in all software packages.
- References: Burrough et al. (1997)
2.4.4.2 Class-based metrics
These metrics are derivatives of the confusion matrix (Congalton and Green 2019a; Fielding and Bell 1997; Kuhn and Johnson 2013) (caret::confusionMatrix())
Beware, measures like overall accuracy and row-wise metrics of the confusion matrix (e.g. user accuracy) are dependent on the prevalence (i.e frequency) of observation in the surveyed area. For example, if dissimilar soils, such as hydric soils, are an inclusions (e.g. 5%) within a survey area, even a poor model could have a overall accuracy of 95%, because small classes by their vary nature don’t contribute significantly to the overall model error. Row-wise metrics by comparison are similarly are impacted by the prevalence or areal extent of soils. Again, more prevalence classes by their vary nature are more likely to be found. The consequence of this is their values are relative to the survey area from which they’re derived (Foody 2010; Kuhn and Johnson 2013, 2019; Eisenberg 1995; Simon and Boring 1990). If the model were extrapolated to an new area or the existing area were subdivided, and the underlying prevalence of classes changed, the row-wise metrics would also be affected. The same is not true for column-wise metrics, because they are conditional on the class being true. Alternative calculations exist for row-wise accuracy that corrects for prevalence, such as the positive predictive value (PPV) and negative predictive value (NPV), which are available via the caret::confusionMatrix function. Similar named functions exist in other R packages, but don’t incorporate the prevalence corrected calculations.
| Confusion Matrix | Observed | Metric | |
|---|---|---|---|
| Predicted | No | Yes | |
| No | True Negative (TN) | False Negative (FN) | NPV/ UA |
| Yes | False Positive (FP) | True Positive (TP) | PPV/ Precision / UA |
| ——————- | ——————– | ——————— | ——————- |
| Metric | Specificity / PA | Sensitivity / PA | Overall |
Accuracy:
- Overall Accuracy:
- Description: The proportion of correctly classified observations as tabulated in the confusion matrix.
- Pro: Simple to calculate and interpret, based entirely on the confusion matrix.
- Con: Does not account for mistakes due to chance. Does not incorporate prior knowledge of class proportions. Does not incorporate class similarity. Does not incorporate information contained within vector of predicted probabilities.
- References: Story and Congalton 1986
- Kappa Coefficient:
- Description: An index that represents the agreement between predicted and observed values and accounts for chance agreement.
- Pro: Easily calculated from the confusion matrix. Generated by most software packages along with the confusion matrix.
- Con: Interpretation of Kappa values between 0 and 1 is largely arbitrary. A value of < 0 indicates no agreement, and a value of 1 indicates perfect agreement. Recommended to use Kappa along with other measures of accuracy. Numerous authors now question the utility and assumptions of Kappa. References: Congalton and Mead (1983); Foody (2020)
- Tau Index:
- Description: An index of agreement that accounts for agreement by chance—effectively a replacement for Kappa (
aqp::tauW()). - Pro: The index is more informative when appropriate class proportions are supplied. Index values can be referenced to concepts such as “better” or “worse” than random allocation.
- Con: Appropriate prior class proportions are method dependent. Interpretation requires some training.
- References: Ma & Remond (1995)
- Description: An index of agreement that accounts for agreement by chance—effectively a replacement for Kappa (
- Weighted Tau Index:
- Description: Alternative version of the tau index that accommodates class similarity. - Pro: The index is more informative when appropriate class proportions are supplied. Class similarity down-weights mistakes between similar classes.
- Con: Appropriate prior class proportions are method dependent. There is no universal method for estimating class similarity weights. Interpretation requires some training.
- References: Rossiter (2017)
- Prevalence (P): % of class occurrence in the population, usually this is estimated from the sample
- Overall Accuracy: % of observations that were correctly classified, for all classes
- Sensitivity (SN) (aka Recall or True Positive Rate):
- TP / (TP + FN)
- % of TRUE predictions that were correctly classified, for an individual class
- Specificity (SP) (aka True Negative Rate):
- TN / (TN + FP)
- errors of commission (Type I)
- % of FALSE observations that were correctly classified, for an individual class
- Precision:
- TP / (TP + FP)
- % of TRUE observations that were classified as a class, that actually were that class
- Positive Predictive Value (PPV):
- if prevalence = 50 then TP / (TP + FP)
- if prevalence != 50 then SN * P / (SN * P) + ((1 - SP) * (1 - P))
- % of TRUE observations that were classified as a class, that actually were that class
- Negative Predictive Value (NPV):
- if prevalence = 50 then TN / (TN + FN)
- if prevalence != 50 then SP * (1 - P) / (P * (1 - SN)) + (SP * (1 - P))
- % of FALSE observations that were classified as a class, that actually were that class
- Producer’s Accuracy (PA):
- diagonal values (TN & TP) / observed values
- % of predictions that were correctly classified, for an individual class
- User’s Accuracy (UA):
- diagonal values / predicted values
- % of FALSE observations that were classified as a class, that actually were that class
Precision/Uncertainty:
- Standard Error (SE):
- Description: Error in the model parameters (e.g., coefficients or overall prediction).
- Confidence Interval (CI):
- Description: Conversion of the SE to an interval according to a given probability (e.g., 95 percent); its range is narrower than the prediction interval.
- Con: Assumes a normal distribution, unless transformed or bootstrapped.
- References:
2.4.5 Examples
url <- "https://raw.githubusercontent.com/ncss-tech/stats_for_soil_survey/master/data/gsp_bs.csv"
bs <- read.csv(url)
bs <- subset(bs, complete.cases(BS2_obs, BS2_pred))
# Probability metrics ----
## Brier score ----
vars <- c("BS2_pred", "BS2_obs")
aqp::brierScore(
bs[vars],
classLabels = "BS2_pred",
actual = "BS2_obs"
)## [1] 0.04872617## D2 & Tjur D2----
modEvA::RsqGLM(
obs = bs$BS2_obs,
pred = bs$BS2_pred,
plot = FALSE
) |>
unlist()## CoxSnell Nagelkerke McFadden Tjur sqPearson
## 0.4205557 0.7920635 0.7207848 0.4775784 0.6169488# Shannon entropy ----
# fake example
test <- seq(0, 0.5, 0.1)
test <- data.frame(obs = test, pred = 1 - test)
cbind(
test,
entropy = apply(test, 1, aqp::shannonEntropy)
)## obs pred entropy
## 1 0.0 1.0 0.0000000
## 2 0.1 0.9 0.4689956
## 3 0.2 0.8 0.7219281
## 4 0.3 0.7 0.8812909
## 5 0.4 0.6 0.9709506
## 6 0.5 0.5 1.0000000## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 0.0000 0.2462 0.4645 0.5033 0.7749 1.0000# Class-based metrics -----
## Confusion matrix ----
# beware caret::confusionMatrix() prefers factors with equal numbers of levels
# also if your table only has 2 classes, you need to specify which is 'positive'
cm1 <- table(pred = as.factor(bs$BS2_pred > 0.5), obs = as.factor(bs$BS2_obs))
cm1## obs
## pred FALSE TRUE
## FALSE 28788 1173
## TRUE 411 3033## Confusion Matrix and Statistics
##
## obs
## pred FALSE TRUE
## FALSE 28788 1173
## TRUE 411 3033
##
## Accuracy : 0.9526
## 95% CI : (0.9502, 0.9548)
## No Information Rate : 0.8741
## P-Value [Acc > NIR] : < 2.2e-16
##
## Kappa : 0.7665
##
## Mcnemar's Test P-Value : < 2.2e-16
##
## Sensitivity : 0.72111
## Specificity : 0.98592
## Pos Pred Value : 0.88066
## Neg Pred Value : 0.96085
## Prevalence : 0.12591
## Detection Rate : 0.09079
## Detection Prevalence : 0.10310
## Balanced Accuracy : 0.85352
##
## 'Positive' Class : TRUE
## ## Examine thresholds ----
library(ROCR)
# generate an prediction object at all possible thresholds
pred <- prediction(bs$BS2_pred, bs$BS2_obs)
# save default plotting parameters
p <- par()
# override default plotting parameter
par(mfrow = c(1, 3), pty = "s")
perf <- performance(pred, "tpr", "fpr")
plot(
perf,
avg = "threshold",
print.cutoffs.at = seq(0.1, 0.9, 0.1),
main = "TPR vs FPR"
)
abline(0, 1)
perf <- performance(pred, "sens", "spec")
plot(
perf,
avg = "threshold",
print.cutoffs.at = seq(0.1, 0.9, 0.1),
main = "Sensitivity vs Specificity"
)
abline(0, 1)
perf <- performance(pred, "sens", "ppv")
plot(
perf,
avg = "threshold",
print.cutoffs.at = seq(0.1, 0.9, 0.1),
main = "Sensitivity vs PPV"
)
abline(0, 1)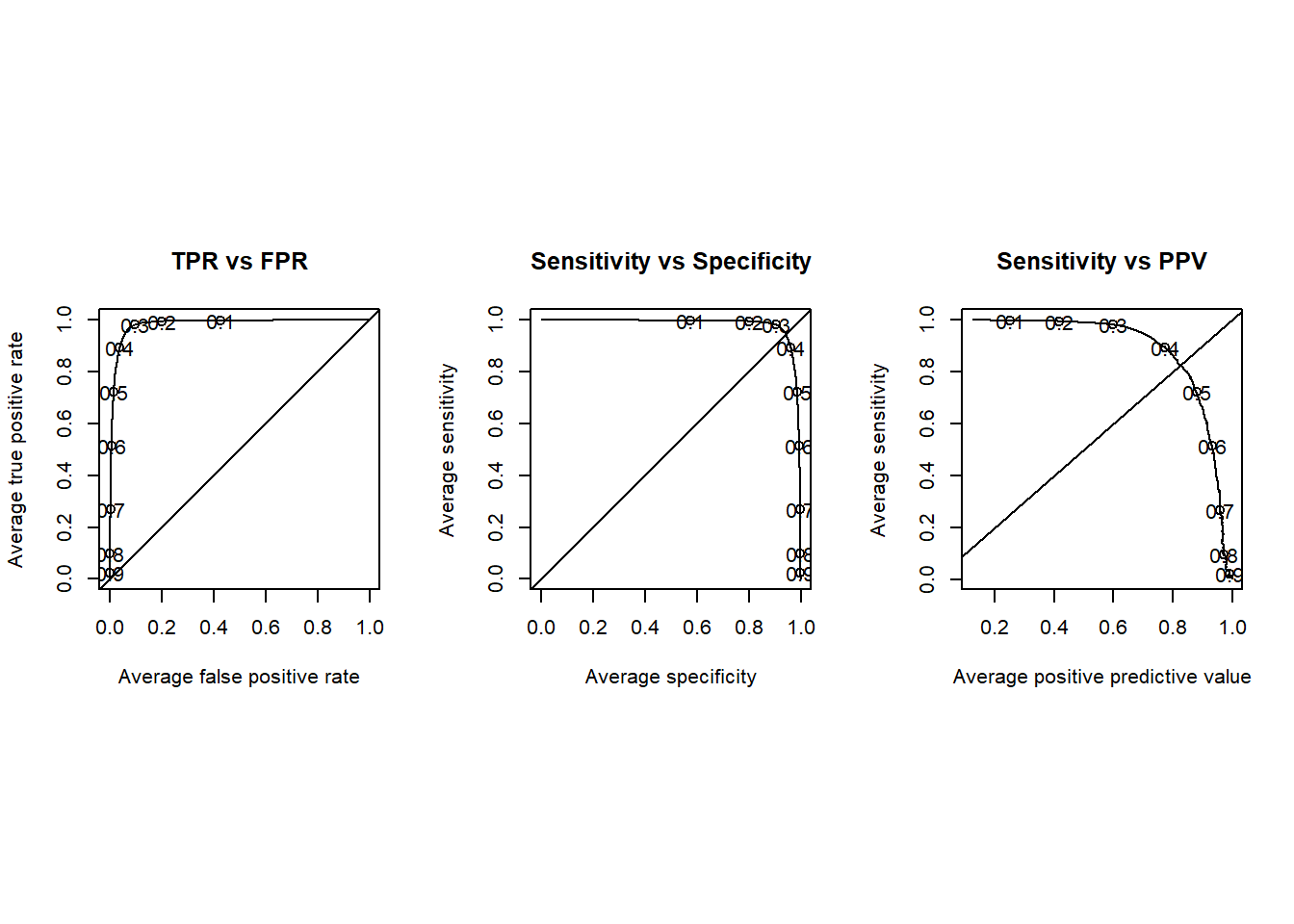
# reset the plotting parameters
par(p)
## Examine overlapping histograms ----
ggplot(bs, aes(x = BS2_pred, fill = BS2_obs)) +
geom_histogram(alpha = 0.5) +
geom_vline(xintercept = 0.50, linetype = "dashed") +
geom_vline(xintercept = 0.45, linetype = "dashed") +
geom_vline(xintercept = 0.33, linetype = "dashed") +
xlab("BS2 Probability")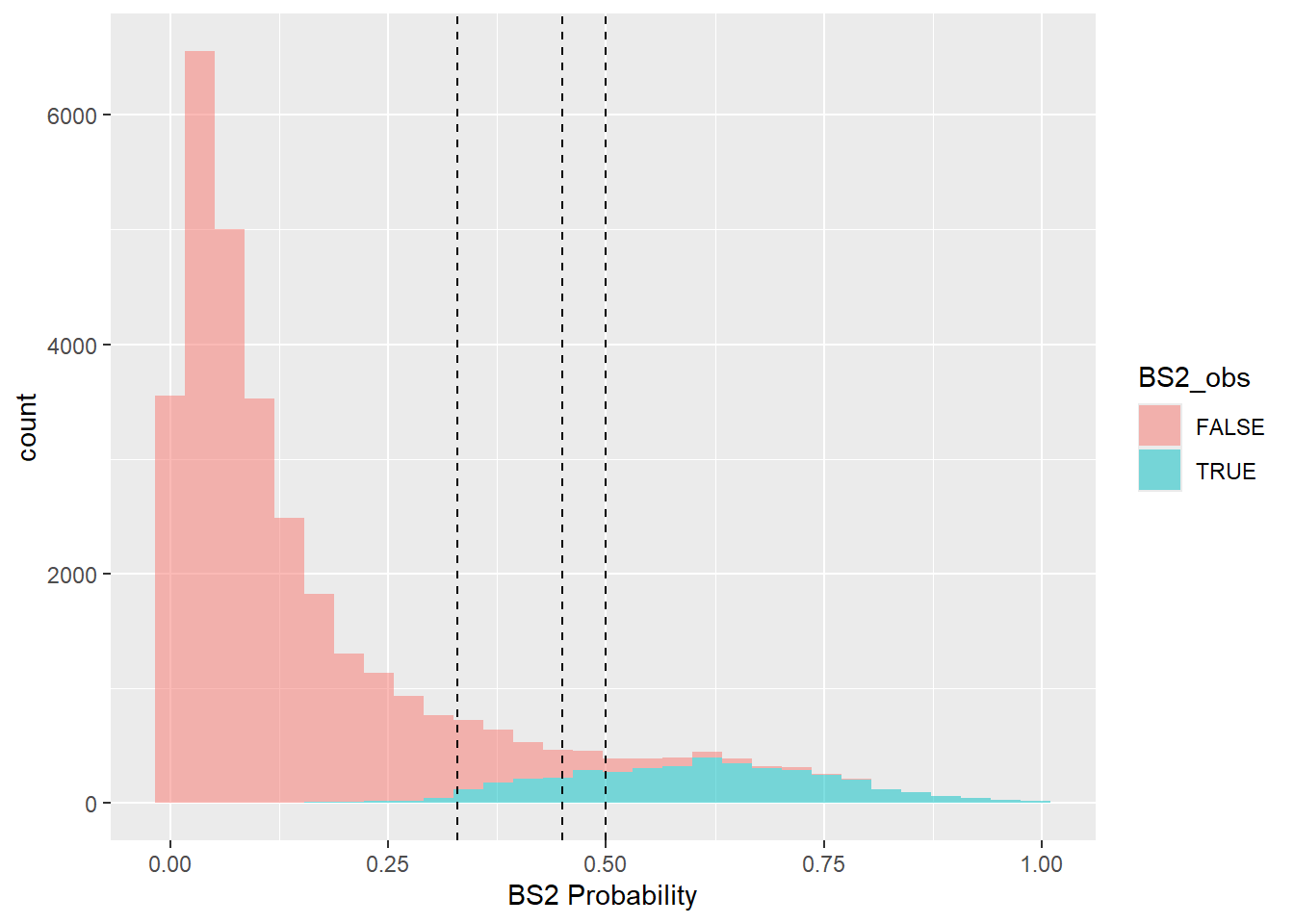
## Trade Precision for Sensitivity by Varying the Threshold
tb <- table(predicted = bs$BS2_pred > 0.45, observed = bs$BS2_obs)
tb## observed
## predicted FALSE TRUE
## FALSE 28519 767
## TRUE 680 3439## Sensitivity Specificity Pos Pred Value
## 0.9767115 0.8176415 0.9738100
## Neg Pred Value Precision Recall
## 0.8349114 0.9738100 0.9767115
## F1 Prevalence Detection Rate
## 0.9752586 0.8740907 0.8537345
## Detection Prevalence Balanced Accuracy
## 0.8766951 0.89717652.4.6 Exercise 3
Append the following exercises to your previous R script.
Calculate the Brier score, \(D^2\) and Shannon Entropy for the
BS1class from thebsdataset.What probably threshold creates the best split for the
BS1class.Calculate a confusion matrix for
sas30_obsvssas30_predfrom thesasdataset. Be sure to manually set the factor levels as shown below.
lev <- unique(c(sas$sas030_obs, sas$sas030_pred))
lev <- lev[c(1, 4, 8, 9, 12, 5, 3, 6, 7, 11)]
sas$sas030_obs <- factor(sas$sas030_obs, levels = lev)
sas$sas030_pred <- factor(sas$sas030_pred, levels = lev)Why can’t you calculate a Brier score and Shannon entropy for the
SASclasses from thesasdataset?Forward you R script your instructor.
2.4.6.1 Stratified-random/areal-adjustment
In the case of stratified-random samples or non-probability samples, it is necessary to adjust the class totals by their known area prior to calculating their accuracy or standard errors (Brus, Kempen, and Heuvelink 2011; Stehman 2014; Campbell, Wynne, and Thomas 2023; Congalton and Green 2019b). This is often the case when a minority class (e.g. minor component or small map unit) is sampled in excess of it’s true proportion relative to the total sample set. This even equal sampling is a good idea in order to adequately sample small but important soil classes (e.g. hydric soils), which will result in greater precision of resulting classes. Surprisingly few R functions to include adjustments for these unequal weights, with the exception of the yardstick, mapac, and MetricsWeighted R packages. The survey R package also has numerous function to analyze design-based survey samples with varying sampling weights. Only the mapac R package provides estimates of the post stratified standard errors for the various confusion matrix derivatives.
In the simplest case where the an existing soil class map is validated by an independent test dataset, it is only necessary to weight the confusion matrix using the prior probabilities of the original map.
# weights
wt <- c(`FALSE` = 0.95, `TRUE` = 0.05)
# confusion matrix
cm <- table(pred = bs$BS2_pred > 0.5, obs = bs$BS2_obs)
cm## obs
## pred FALSE TRUE
## FALSE 28788 1173
## TRUE 411 3033## obs
## pred FALSE TRUE
## FALSE 0.913 0.037
## TRUE 0.006 0.044## obs
## pred FALSE TRUE
## FALSE 30492 1242
## TRUE 199 1471# compare weighted and unweighted confusion matrices
caret::confusionMatrix(cm, positive = "TRUE")$byClass## Sensitivity Specificity Pos Pred Value
## 0.72111270 0.98592418 0.88066202
## Neg Pred Value Precision Recall
## 0.96084910 0.88066202 0.72111270
## F1 Prevalence Detection Rate
## 0.79294118 0.12590930 0.09079479
## Detection Prevalence Balanced Accuracy
## 0.10309834 0.85351844## Sensitivity Specificity Pos Pred Value
## 0.54220420 0.99351601 0.88083832
## Neg Pred Value Precision Recall
## 0.96086217 0.88083832 0.54220420
## F1 Prevalence Detection Rate
## 0.67122975 0.08121782 0.04403664
## Detection Prevalence Balanced Accuracy
## 0.04999401 0.76786011However as is often the case, when the samples are stratified using environmental covariates the strata don’t coincide with the resulting digital soil map, and therefore the accuracy and errors within each strata need to be estimated separately and then averaged using the strata sizes as weights (Brus, Kempen, and Heuvelink 2011; Stehman 2014). The sample weights will equal the total number of pixels each sample represents.
library(mapac)
library(survey)
exdata <- aa_examples("stehman2014")
# post stratified confusion matrix
cm <- aa_stratified(
stratum = exdata$stratum,
reference = exdata$ref,
map = exdata$map,
h = exdata[["h"]],
N_h = exdata[["N_h"]]
)
cm$cmp * sum(exdata$N_h)## A B C D
## A 23000 4000 4000 0
## B 12000 27000 8000 0
## C 0 2000 6000 4000
## D 0 1000 2000 7000## class ua ua_se pa pa_se f1 f1_se
## 1 A 0.7419355 0.1645627 0.6571429 0.1477318 0.6969697 0.11034620
## 2 B 0.5744681 0.1248023 0.7941176 0.1165671 0.6666667 0.09354009
## 3 C 0.5000000 0.2151657 0.3000000 0.1504438 0.3750000 0.13219833
## 4 D 0.7000000 0.1527525 0.6363636 0.1623242 0.6666667 0.11284328# compute stratum weights
W <- exdata$N_h / as.integer(table(exdata$stratum))
names(W) <- exdata$h
ex <- data.frame(exdata[1:3], stringsAsFactors = FALSE)
ex[1:3] <- lapply(ex, as.factor)
ex <- within(ex, {
w = W[match(stratum, names(W))]
ref_A = factor(ifelse(reference == "A", "yes", "no"))
map_A = factor(ifelse(map == "A", "yes", "no"))
})
# weighted sensitivty from yardstick
yardstick::sens(
ex,
truth = ref_A,
estimate = map_A,
case_weights = w,
event_level = "second"
)## # A tibble: 1 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 sens binary 0.657# weight the confusion matrix
ex_svy <- svydesign(ids = ~1, weights = ~w, strata = ~stratum, data = ex, variables = ~map+reference)
tb <- svytable(~map+reference, design = ex_svy)
tb## reference
## map A B C D
## A 23000 4000 4000 0
## B 12000 27000 8000 0
## C 0 2000 6000 4000
## D 0 1000 2000 7000## Sensitivity Specificity Pos Pred Value Neg Pred Value Precision
## Class: A 0.6571429 0.8769231 0.7419355 0.8260870 0.7419355
## Class: B 0.7941176 0.6969697 0.5744681 0.8679245 0.5744681
## Class: C 0.3000000 0.9250000 0.5000000 0.8409091 0.5000000
## Class: D 0.6363636 0.9662921 0.7000000 0.9555556 0.7000000
## Recall F1 Prevalence Detection Rate Detection Prevalence
## Class: A 0.6571429 0.6969697 0.35 0.23 0.31
## Class: B 0.7941176 0.6666667 0.34 0.27 0.47
## Class: C 0.3000000 0.3750000 0.20 0.06 0.12
## Class: D 0.6363636 0.6666667 0.11 0.07 0.10
## Balanced Accuracy
## Class: A 0.7670330
## Class: B 0.7455437
## Class: C 0.6125000
## Class: D 0.80132792.5 Validation
Validation refers to the process and the result of a process where the validity of a model is tested. That is, how well does the model represent reality? There are varying degrees of formality and thoroughness that can be used in validation. While multiple stages of the modeling process can be validated, usually it’s the output of the model that is investigated and reported. You can group initial validation into three broad groups: Expert evaluation, Theoretical Analysis and Prediction Accuracy.
Expert Evaluation: In this case, the model output is inspected by an expert user. The first evaluator will be you (the developer), but ideally an outside expert will be utilized. This is often a step in an iterative process. Evaluate the model output, does it make sense, do you see things that need to be improved? Then make changes to the model to improve the output.
Theoretical Analysis: compare the results of the model to what is theoretically possible. In systems modeling, this might include diagnostics statistics including residual analysis, cross-correlation of variables and outputs, sensitivity analysis and model analysis such as Akaike Information Criterion (AIC). This can also include simple comparison of output to known possible values. This is especially important for linear regression where the slope of the model is assumed to be steady no matter the values of the dependent variables.
Prediction Accuracy: The correctness of the parameter being predicted by the model (soil taxa, property etc.). Ideally this is done with an independent set of data.
In soil science, we typically use the term model validation to refer to a statistical analysis that assesses how well a model will predict at an unknown location. A complete model should have a formal statistical evaluation that can be reported and stored as model and output meta-data. That is the portion of validation we will focus. For this discussion, validation can be thought of as an assessment of prediction error and variance.
Three types of validation used in the course
- Internal - Performance on population underlying the sample
- External - Performance on related (similar/adjacent) but independent population
2.5.1 Internal Validation
2.5.1.1 Split-sample - A single partition of the data into a learning and a calibration set.
- Achieve an independent validation by partitioning the samples into calibration or training and validation data-sets (70% of the samples available are recommended for calibration)
- Build model on calibration (training) data-set
- Test model on validation (test) data-set
- Report accuracy on the validation data-set
- This method is relatively simple (conceptually and computationally). Results depend on having an adequate sample size to both develop and test the model.
2.5.1.2 Cross-validation - Alternate development and validation
Leave-One-Out Cross-Validation (LOOCV)
- One observation is used for testing and all others are used to develop model
- Repeat n (total number of observations) times
- Average error over n
- The mean of the accuracy is the expected accuracy of the model (this assumes that new data is from the same population) (Efron, 1983)
k-fold Cross-Validation (k-fold) CV
- Randomly divide observations into calibration and validation sets.
- Repeat k times, each time one k group is used for error estimates
- Average error of k
- Less computationally intensive than LOOCV, but it is more robust and can be done with smaller sample sizes than a simple split.
- Several R packages have tools to cross-validate predictions, including:
DAAGandbootforlm()andglm()objects,caret,rms,
### Linear model example
# Create folds
folds <- createFolds(1:nrow(sas), k = 10)
# Cross validate
lm_cv <- lapply(folds, function(x) {
train = sas[-x,]
test = sas[x,]
obs = test$pH_0.30_obs
# predict = predict(model, test)
pred = test$pH_0.30_pred
RMSE = RMSE(pred, obs, na.rm = TRUE)
R2 = R2(pred, obs, formula = "traditional", na.rm = TRUE)
return(c(RMSE = RMSE, R2 = R2))
})
# Convert to a data.frame
lm_cv <- do.call(rbind, lm_cv)
# Summarize results
summary(lm_cv)## RMSE R2
## Min. :0.4594 Min. :0.8460
## 1st Qu.:0.4643 1st Qu.:0.8488
## Median :0.4682 Median :0.8538
## Mean :0.4690 Mean :0.8526
## 3rd Qu.:0.4738 3rd Qu.:0.8562
## Max. :0.4781 Max. :0.85722.5.1.3 Subsample (Resampling or sample simulation)
In this method, the ‘leave-out’ method can be random (Bootstrap) or observation selection can use a more sophisticated method to select observations to represent the population including Monte Carlo (Molarino, 2005) and .632+bootstrap of Efron & Tibshirani (1997). The details of those aren’t important, except to know that they can give you a better idea of the robustness of your model.
- As with re-sampling for uncertainty estimation, observations are repeatedly sampled
- Select a number of samples (Randomly or from known distribution).
- Develop the model
- Estimate model accuracy on unselected samples
- Repeat the process (with independent sample) a large number of times, 500 - 5,000.
- The expected model accuracy is then the mean of the estimates.
NOTE: The BEST model should not be assumed to be the one that makes the ‘truest’ predictions. Beware of over-fitting. When a model is over-fit, it predicts due to very specific “quirks” in the calibration data set and not due to explanatory relationships that will apply to validation and independent data-sets. One strategy to avoid this situation is to build models with as few variables as possible. Parsimonious models (those that use the least amount of information possible to obtain the same result or convey the same meaning) often have higher predicative validity. The use of metrics such as Akaike’s Information Criterion (AIC) can be helpful for balancing error and parameter minimization.
2.5.2 External Validation
In this case, an independent data-set is used as the test case.
- Independent observations predicted with model
- Errors (ME, RMSE) calculated on predicted vs. actual
- Some exploratory analysis can be helpful to diagnose and explain model performance.
The use of validation will be demonstrated as part of each modeling section. The size of the data-set used, understanding of the variables involved and the nature of the statistical models and algorithms used all influence which validation techniques are most convenient and appropriate.