Chapter 5 Generalized Linear Models
![]()
5.1 Introduction
Generalized linear models (GLM) as the name implies are a generalization of the linear modeling framework to allow for the modeling of response variables (e.g. soil attributes) with non-normal distributions and heterogeneous variances. Whereas linear models are designed for predicting continuous soil properties such as clay content or soil temperature, GLM can be used to predict the presence/absence of argillic horizons (i.e. logistic regression) or counts of a plant species along a transect (i.e. Poisson regression). These generalizations greatly expand the applicability of the linear modeling framework, while still allowing for a similar fitting procedure and interpretation of the resulting models.
In the past in order to handle non-linearity and heterogeneous variances, transformations have been made to the response variable, such as the log(y). However, such transformations complicate the models interpretation because the results refer to the transformed scale (e.g. log(y))(Lane 2002). These response transformations are not guaranteed to achieve both normality and constant variance simultaneously. GLM approaches transform the response, but also preserve the scale of the response, and provide separate functions to transform the mean response and variance, known as the link and variance functions respectively. So instead of looking like this:
\(f(y) = \beta_{0} + \beta_{1}x + \varepsilon\)
you get this:
\(g(\mu)\) or \(\eta = \beta_{0} + \beta_{1}x + \varepsilon\)
with \(g(\mu)\) or \(\eta\) symbolizing the link function.
Another alteration of the classical linear model is that with GLM the coefficients are estimated iteratively by maximum likelihood estimation instead of ordinary least squares. This results in the GLM minimizing the deviance, instead of the sum of squares. However, for the Gaussian (i.e. normal) distributions the deviance and sum of squares are equivalent.
5.2 Logistic Regression
Logistic regression is a specific type of GLM designed to model data that has a binomial distribution (i.e. presence/absence, yes/no, or proportional data), which in statistical learning parlance is considered a classification problem. For binomial data the logit link transform is generally used. The effect of the logit transform can be seen in the following figure. It creates a sigmoidal curve, which enhances the separation between the two groups. It also has the effect of ensuring that the values range between 0 and 1.
## Warning: package 'ggplot2' was built under R version 4.5.2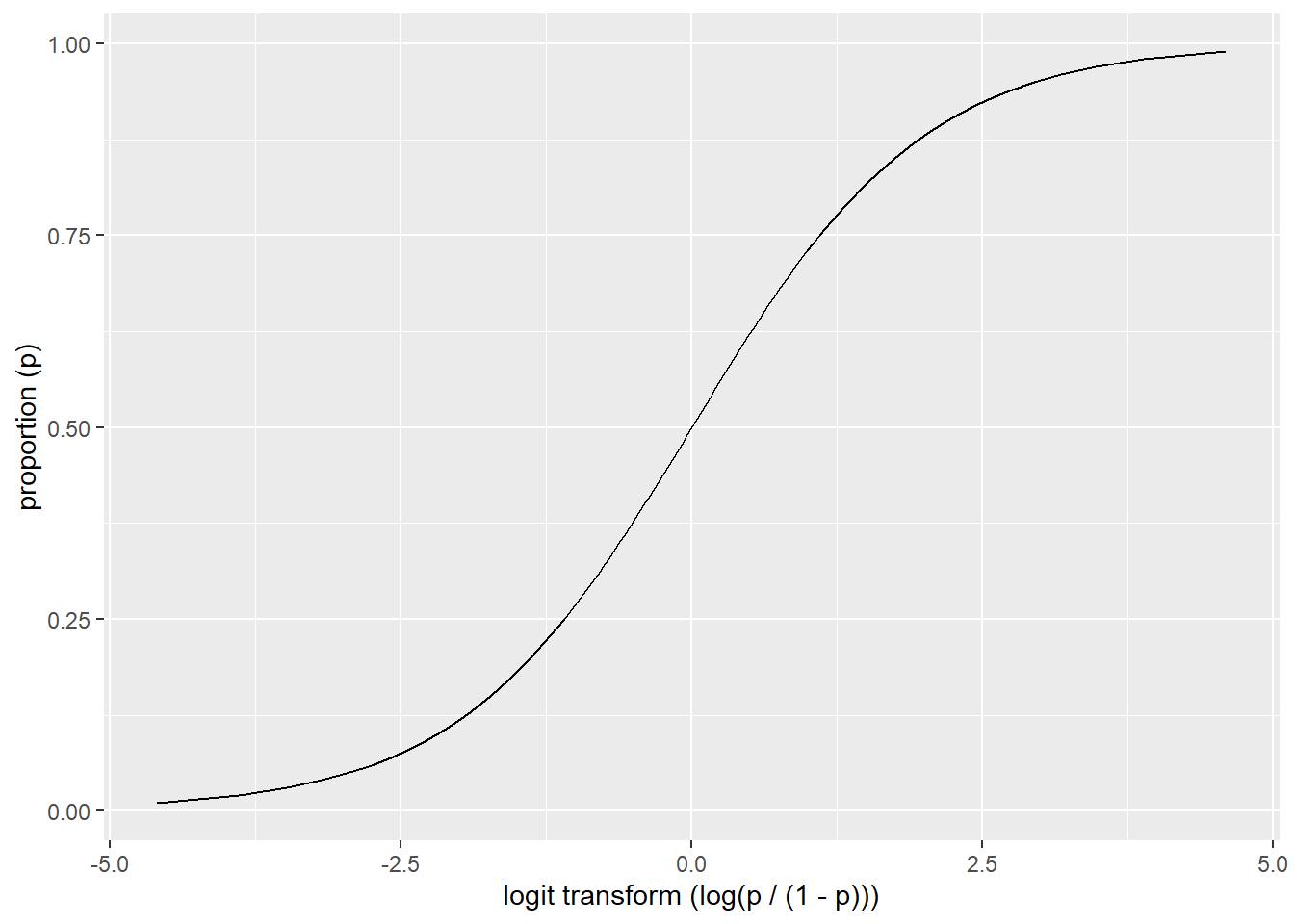
When comparing a simple linear model vs a simple logistic model we can see the effect of the logit transform on the relationship between the response and predictor variable. As before it follows a sigmoidal curve and prevents predictions from exceeding 0 and 1.
## Warning: Removed 19 rows containing missing values or values outside the scale range
## (`geom_line()`).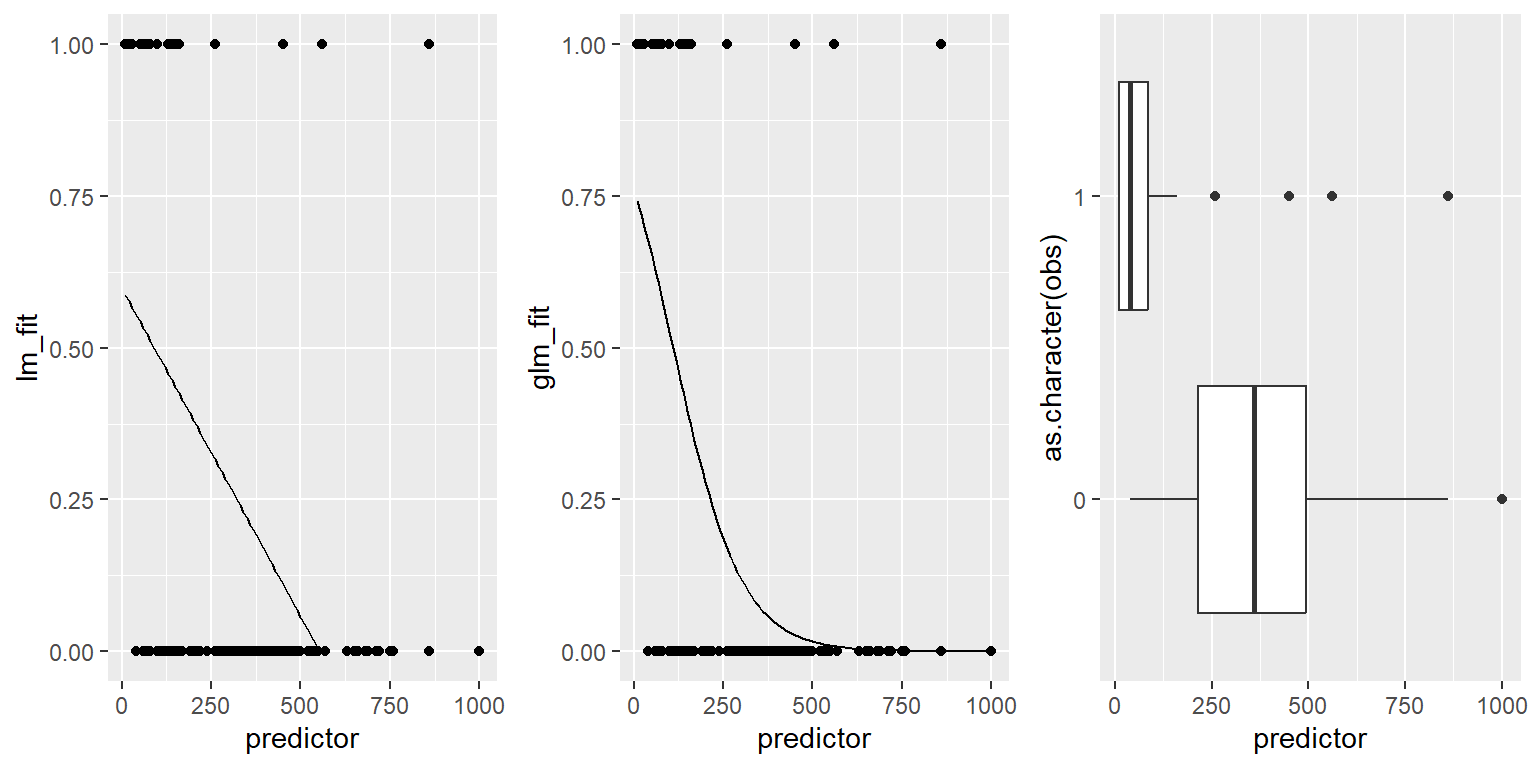
5.3 Examples

5.4 Exercise
Now that we’ve discussed some of the basic background GLM theory we’ll move on to a real exercise, and address any additional theory where it relates to specific steps in the modeling process. The examples selected for this chapter come from Joshua Tree National Park (JTNP)(i.e. CA794) in the Mojave desert. The problem tackled here is a familiar one: Where can I expect to find argillic horizons on fan piedmonts? Argillic horizons within the Mojave are typically found on fan remnants, which are a stable landform that is a remnant of the Pleistocene (Peterson 1981). Despite the low relief of most fans, fan remnants are uplands in the sense that they generally don’t receive run-on or active deposition.
With this dataset we’ll encounter some challenges. To start with, fan piedmont landscapes typically have relatively little relief. Since most of our predictors will be derivatives of elevation, that won’t leave us with much to work with. Also, our elevation data comes from the USGS National Elevation dataset (NED), which provides considerably less detail than say LiDAR or IFSAR data (Shi et al. 2012). Lastly our pedon dataset like most in NASIS, hasn’t received near as much quality control as have the components. So we’ll need to wrangle some of the pedon data before we can analyze it. These are all typical problems encountered in any data analysis and should be good practice. Ideally, it would be more interesting to try and model individual soil series with argillic horizons, but due to some of the challenges previously mentioned it would be difficult with this dataset. However, at the end we’ll look at one simple approach to try and separate individual soil series with argillic horizons.
5.4.1 Load packages
To start, as always we need to load some extra packages. This will become a familiar routine every time you start R. Most of the basic functions we need to develop a logistic regression model are contained in base R, but the following contain some useful spatial and data manipulation functions. Believe it or not we will use all of them and more.
library(aqp) # soil data classes
library(raster) # raster data functions
library(sf) # vector data functions
library(mapview) # interactive mapping
library(ggplot2) # graphing
library(dplyr) # data manipulation
library(tidyr) # data manipulation
library(rms) # additional regression tools
library(caret) # additional modeling tools5.4.2 Read in data
Hopefully like all good soil scientists and ecological site specialists you enter your field data into NASIS. Better yet hopefully someone else did it for you! Once data are captured in NASIS it is much easier to import the data into R, extract the pieces you need, manipulate it, model it, etc. If it’s not entered into NASIS, it may as well not exist. For this exercise we’ll load a cached dataset on GitHub.
5.5 Exploratory analysis (EDA)
5.5.1 Data wrangling
Generally before we begin modeling you should spend some time exploring the data. By examining a simple summary we can quickly see the breakdown of how many argillic horizons we have. Unfortunately, odds are good that all the argillic horizons haven’t been consistently populated in the diagnostic horizon table like they should be. Luckily for us, the desert argillic horizons always pop up in the taxonomic name, so we can use pattern matching to extract it. By doing this we gain an additional 11 pedons with argillic horizons and are able to label the missing values (i.e. NA). At a minimum for modeling purposes we probably need 10 pedons of the target we’re interested in and a total of 100 observations overall.
# Check consistency of argillic horizon population
# extract the site table from the SoilProfileCollection object
s <- site(pedons)
# tabulate column
count(s, argillic.horizon)## argillic.horizon n
## 1 FALSE 790
## 2 TRUE 263
## 3 NA 167# Extract argillic presence from the taxonomic subgroup
s <- mutate(s, argillic = grepl("arg", taxsubgrp))
# tabulate column
count(s, argillic)## argillic n
## 1 FALSE 1022
## 2 TRUE 198Ideally, if the diagnostic horizon table had been populated consistently we could have used the upper depth to diagnostic feature to filter out argillic horizons that start below 50cm, which may not be representative of “good” argillic horizons and may therefore have gotten correlated to a Torripsamments anyway. Not only are unrepresentative sites confusing for scientists, they’re equally confusing for models. However, as we saw earlier, some pedons don’t appear to be fully populated, so we’ll stick with those pedons that have the argillic specified in their taxonomic subgroup name, since it gives us the biggest sample.
# extract the diagnostic table from the SoilProfileCollection object
diagnostic_hz(pedons) %>%
# create a new variable
mutate(argillic.horizon50 = featkind == "argillic horizon" & featdept < 50) %>%
# tabulate column
count(argillic.horizon50)## argillic.horizon50 n
## 1 FALSE 1935
## 2 TRUE 222
## 3 NA 45.5.2 Geomorphic data
Another obvious place to look is at the geomorphic data in the site table. This information is intended to help differentiate where our soil observations exist on the landscape. If populated consistently it could potentially be used in future disaggregation efforts, as demonstrated by Nauman and Thompson (2014).
# Landform vs argillic presence
s %>%
# subset rows using logical expression
filter(argillic == TRUE) %>%
# cross-tabulate columns
count(landform, argillic) %>%
# subset rows by landform.string with > 3 observations
filter(n > 3) %>%
# sort data by decreasing n
arrange(-n)## landform argillic n
## 1 fan remnants TRUE 72
## 2 hillslopes TRUE 28
## 3 fan aprons TRUE 19
## 4 hills TRUE 15
## 5 pediments TRUE 9
## 6 mountain slopes TRUE 8
## 7 <NA> TRUE 7
## 8 alluvial fans TRUE 6
## 9 low hills TRUE 5
## 10 fan aprons on fan remnants TRUE 4
## 11 mountains TRUE 4# generalize the landform.string
s <- mutate(
s,
landform_generic = ifelse(grepl("fan|terrace|sheet|drainageway|wash", s$landform), "fan", "hill")
)Examining the above frequency table we can see that argillic horizons occur predominantly on fan remnants as was alluded too earlier. However, they also seem to occur frequently on other landforms - some of which are curious combinations of landforms or redundant terms.
# Hillslope position
# # subset rows using logical expression
s_sub <- filter(s, landform_generic == "fan")
# Hillslope
s_sub %>%
# cross-tabulate columns
count(hillslopeprof, argillic) %>%
# group by variable and calculate percent
group_by(argillic) %>%
mutate(pct = round(n / sum(n) * 100)) %>%
# reshape to wide format
select(-n) %>%
pivot_wider(names_from = argillic, values_from = pct)## # A tibble: 6 × 3
## hillslopeprof `FALSE` `TRUE`
## <fct> <dbl> <dbl>
## 1 summit 16 39
## 2 shoulder 4 2
## 3 backslope 14 20
## 4 footslope 2 1
## 5 toeslope 16 4
## 6 <NA> 48 34# slope shape
s_sub %>%
# create a new variable
mutate(SS = paste(shapedown, shapeacross)) %>%
# cross-tabulate columns
count(SS, argillic) %>%
# calculate percent by group
group_by(argillic) %>%
mutate(pct = round(n / sum(n) * 100)) %>%
# reshape to wide format
select(-n) %>%
pivot_wider(names_from = argillic, values_from = pct)## # A tibble: 11 × 3
## SS `FALSE` `TRUE`
## <chr> <dbl> <dbl>
## 1 NA NA 11 10
## 2 concave concave 1 NA
## 3 concave convex 0 NA
## 4 concave linear 4 3
## 5 convex concave 0 1
## 6 convex convex 7 7
## 7 convex linear 6 9
## 8 linear NA 0 NA
## 9 linear concave 6 1
## 10 linear convex 21 32
## 11 linear linear 44 38Looking at the hillslope position of fan landforms we can see a slightly higher proportion of argillic horizons are found on summits, while less are found on toeslopes. Slope shape doesn’t seem to provide any useful information for distinguishing argillic horizons.
s_long <- s %>%
# subset rows using logical expression
filter(landform_generic == "fan") %>%
# extract columns
select(argillic, bedrckdepth, slope, elev, surface_total_frags_pct) %>%
# reshape to long format
pivot_longer(cols = c(bedrckdepth, slope, elev, surface_total_frags_pct))
# examine results
head(s_long)## # A tibble: 6 × 3
## argillic name value
## <lgl> <chr> <dbl>
## 1 FALSE bedrckdepth NA
## 2 FALSE slope 28
## 3 FALSE elev 1761
## 4 FALSE surface_total_frags_pct 85
## 5 FALSE bedrckdepth 11
## 6 FALSE slope 60# plot results
ggplot(s_long, aes(x = argillic, y = value)) +
geom_boxplot() +
facet_wrap(~ name, scale = "free")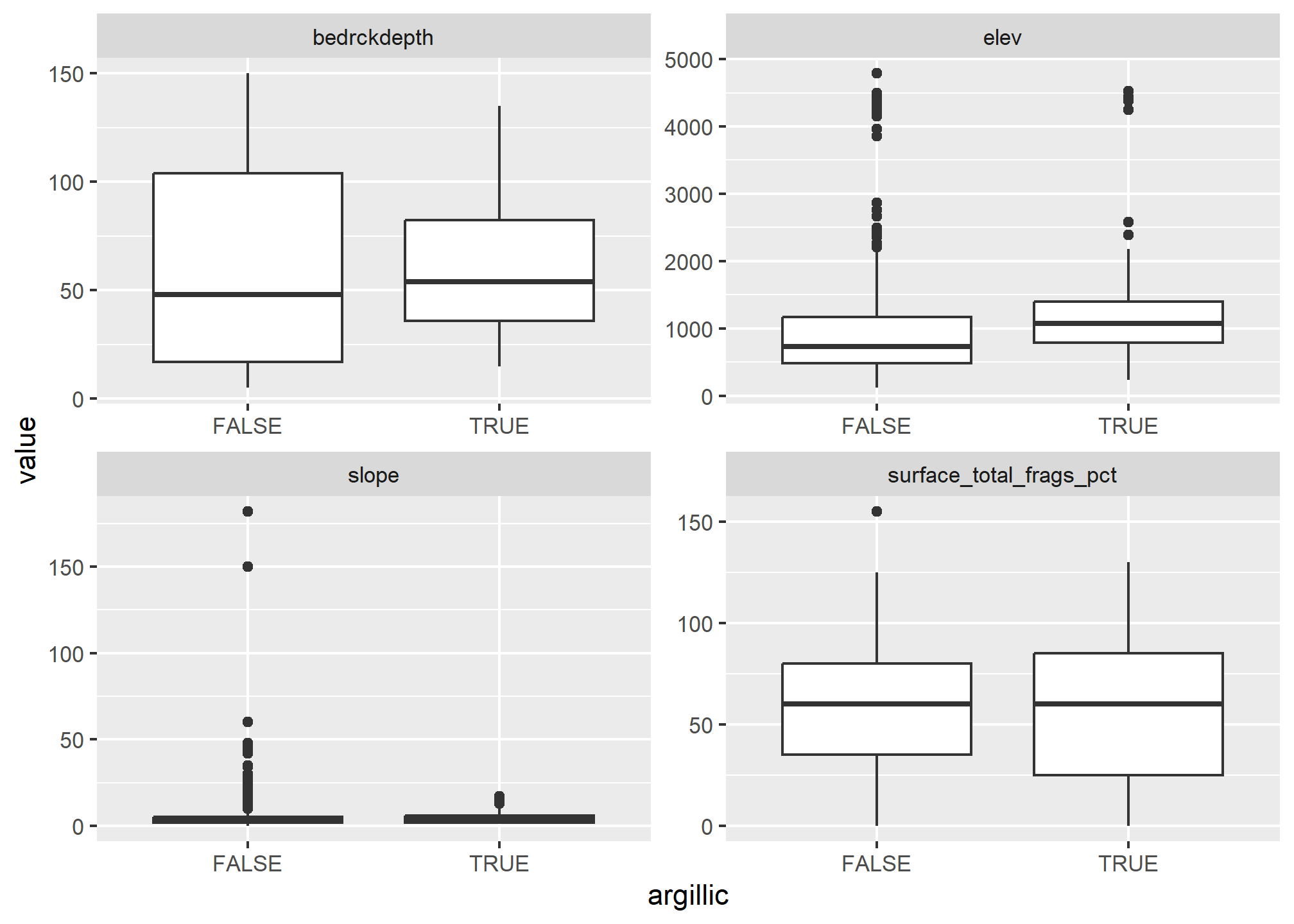
Looking at boxplots of our numeric variables we can see none of them show much separation between the presense/absense of argillic horizons.
5.5.3 Soil Scientist Bias
Next we’ll look at soil scientist bias. The question being: Are some soil scientists more likely to describe argillic horizons than others? Due to the excess number of soil scientist that have worked on CA794, including detailees, we’ve filtered the names of soil scientist to include just the top 3 mappers and given priority to the most senior soil scientists when they occur together.
# Filter and sort most frequent soil scientists by seniority
s <- mutate(
s,
old = descname,
descname2 = NA,
descname2 = ifelse(grepl("Stephen", old), "Stephen", descname2), # least senior
descname2 = ifelse(grepl("Paul", old), "Paul", descname2),
descname2 = ifelse(grepl("Peter", old), "Peter", descname2) # most senior
)s %>%
# subset rows using logical expression
filter(landform_generic == "fan") %>%
# cross-tabulate columns
count(descname2, argillic) %>%
# calculate percent by group
group_by(descname2) %>%
mutate(pct = round(n / sum(n) * 100)) %>%
# reshape the results into a table
select(-n) %>%
pivot_wider(names_from = argillic, values_from = pct)## # A tibble: 4 × 3
## # Groups: descname2 [4]
## descname2 `FALSE` `TRUE`
## <chr> <dbl> <dbl>
## 1 Paul 73 27
## 2 Peter 90 10
## 3 Stephen 84 16
## 4 <NA> 78 22For fan landforms, one of the soil scientists seems more likely than the others to describe argillic horizons. However while this information is suggestive, it is far from definitive in showing a potential bias because it doesn’t take into account other factors. We’ll examine this more closely later.
5.5.4 Plot coordinates
Where do our points plot? To start we need to convert them to a spatial object first. Then we can create an interactive we map using mapview. Also, if we wish we can also export the locations as a Shapefile.
# subset rows with only complete X & Y coordinates
s_sub <- filter(s, complete.cases(x_std, y_std))
# convert s_sub data.frame to a spatial object
s_sf <- st_as_sf(s_sub,
# define coordinates
coords = c("x_std", "y_std"),
# define coordinate reference system using ESPG code
crs = 4326
) %>%
# reproject to equal area coordinate reference system using ESPG code
st_transform(crs = 5070)
# Download soil survey area boundaries
ca794 <- soilDB::fetchSDA_spatial("CA794", geom.src = "sapolygon") %>%
# convert to spatial object
st_as_sf() %>%
# reproject to equal area coordinate reference system using ESPG code
st_transform(crs = 5070)
# Plot interactive map
mapview(ca794, alpha.regions = 0, lwd = 2) +
mapview(s_sf, zcol = "argillic")
5.6 Exercise 1: View the data
- Examine the interactive map.
- Hypothesize what predictor variables/landscape relationships might be predictive.
5.6.1 Extracting spatial data
Prior to any spatial analysis or modeling, you will need to develop a suite of geodata files that can be intersected with your field data locations. This is, in and of itself a difficult task, and should be facilitated by your Regional GIS Specialist. Typically, these geodata files would primarily consist of derivatives from a DEM or satellite imagery. Prior to any prediction it is also necessary to ensure the geodata files have the same projection, extent, and cell size. Once we have the necessary files we can construct a list in R of the file names and paths, read the geodata into R, and then extract the geodata values where they intersect with field data.
# load raster stack from GitHub
githubURL <- url("https://raw.githubusercontent.com/ncss-tech/stats_for_soil_survey/master/data/ca794_rs.rds")
geodata_r <- readRDS(githubURL)
# Extract the geodata and add to a data frame
data <- raster::extract(geodata_r, as(s_sf, "Spatial"), sp = TRUE)@data
# Modify some of the geodata variables
data <- mutate(
data,
cluster = factor(cluster),
twi_sc = abs(twi - 13.8), # 13.8 = twi median
gsi = (ls_3 - ls_1) / (ls_3 + ls_2 + ls_1),
ndvi = (ls_4 - ls_3) / (ls_4 + ls_3),
)5.6.2 Examine spatial data
With our spatial data in hand, we can now see whether any of the variables will help us separate the presence/absence of argillic horizons. Because we’re dealing with a classification problem, we’ll compare the numeric variables using boxplots. What we’re looking for are variables with the least amount of overlap in their distribution (i.e. the greatest separation in their median values).
URL <- url("https://raw.githubusercontent.com/ncss-tech/stats_for_soil_survey/master/data/ch7_data.Rdata")
load(URL)
train <- data
# Select argillic horizons with "arg" in the subgroup name and on fans
# Argillic horizons that occur on hills and mountains more than likely form by different process, and therefore would require a different model.train$argillic
train <- mutate(
train,
argillic = factor(ifelse(grepl("arg", taxsubgrp) & train$mrvbf > 0.15, "yes", "no")),
ch_log = log(ch + 1),
z2str_log = log(z2str + 1),
ch = NULL,
z2str = NULL
)
train <- select(train, c(argillic, z:z2str_log))
data_l <- train %>%
select(-cluster, -geo) %>%
pivot_longer(col = - argillic) %>%
filter(!is.na(value))
ggplot(data_l, aes(x = argillic, y = value)) +
geom_boxplot() +
facet_wrap(~ name, scales = "free")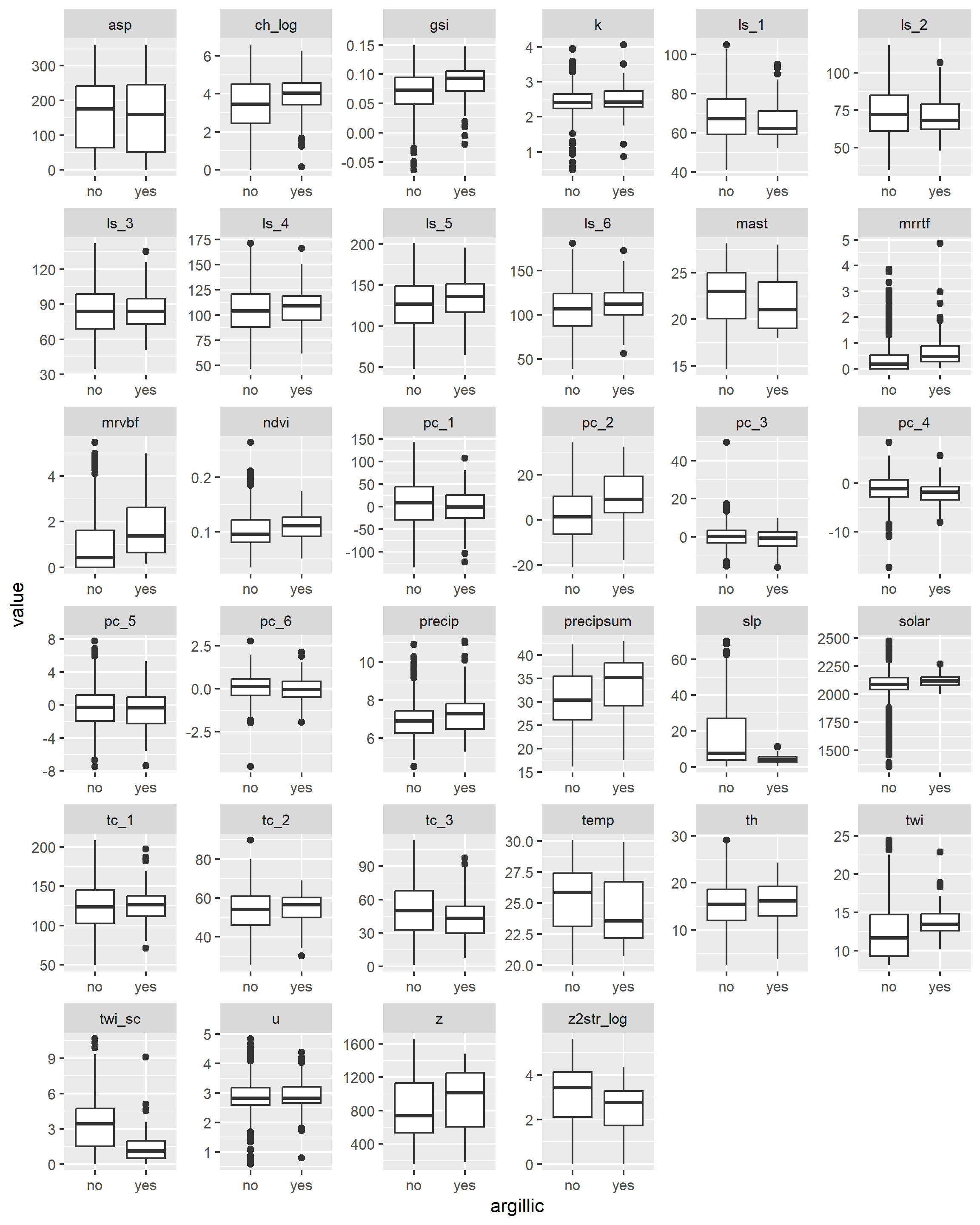
5.7 Constructing the model
R has several functions for fitting linear models. The most common is arguably the glm() function from the stats R package, which is loaded by default. The glm() function is also extended thru the use of several additional packages such as the car and caret R packages. Another noteworthy R package for logistic regrssion is rms, which offers the lrm() function. The rms R package (Harrell 2015) offers an ‘almost’ comprehesive alternative to glm() and it’s accessory function. It is difficult to objectively functions say which approach is better. Therefore methods both methods will be demonstrated. Look for comments (i.e. #) below referring to rms, stats, caret or visreg.
# stats
fit_glm <- glm(argillic ~ z + slp + twi_sc + ch_log + z2str_log + mrrtf + solar + precip + precipsum + temp +tc_1 + tc_2 + tc_3 + k + th + u + cluster, data = train, family = binomial)
# rms
library(rms)
dd <- datadist(train)
options(datadist = "dd")
fit_lrm <- lrm(argillic ~ z + slp + twi_sc + ch_log + z2str_log + mrrtf + solar + precip + precipsum + temp + tc_1 + tc_2 + tc_3 + k + th + u, data = train, x = TRUE, y = TRUE)5.7.1 Diagnostic
5.7.1.1 Residual plots
One unfortunate side effect of side effect of logistic regression is that the default residual plots are not interpretable. However the partial residual plots can be useful for identifying outliers and nonlinear trends.
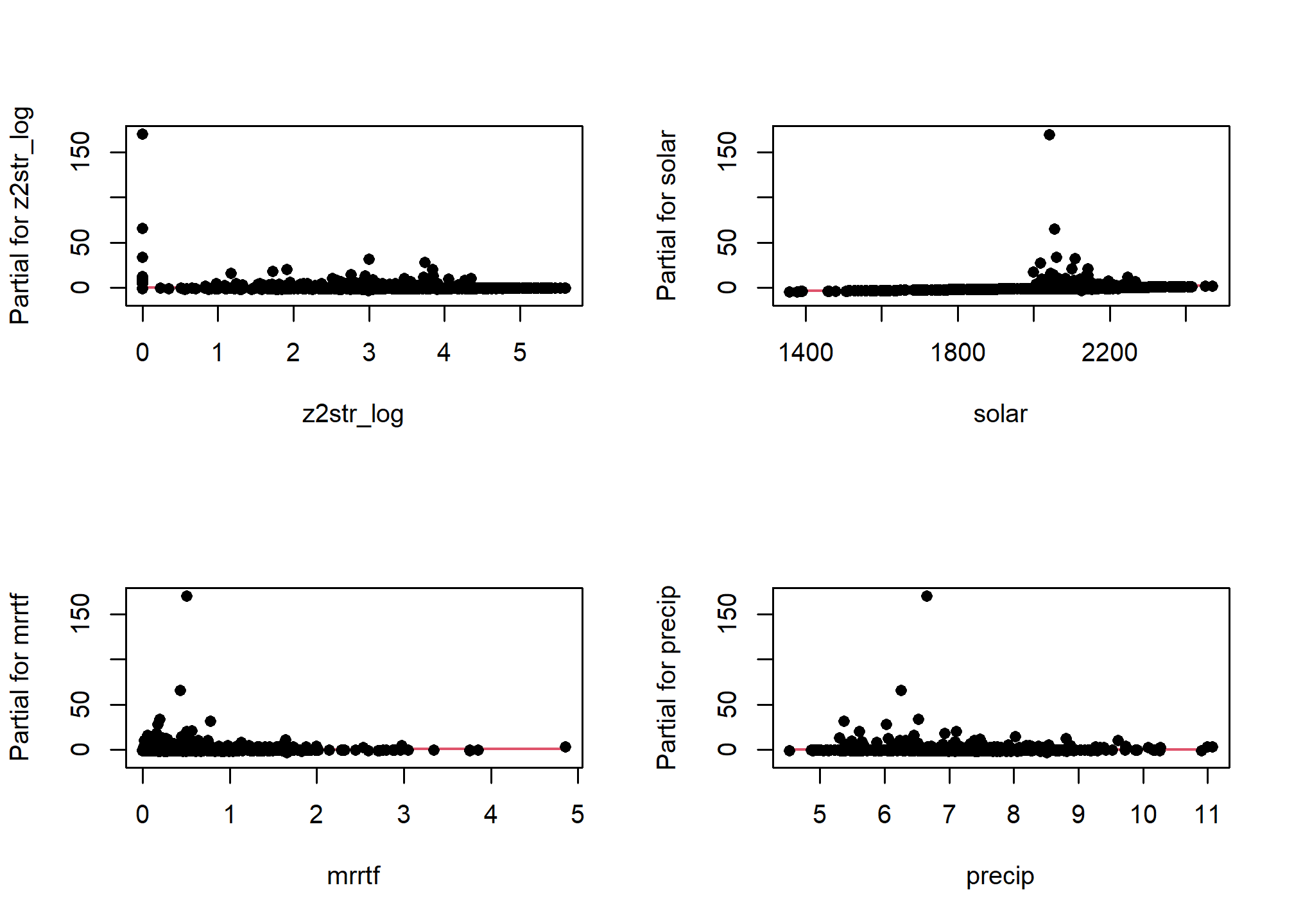
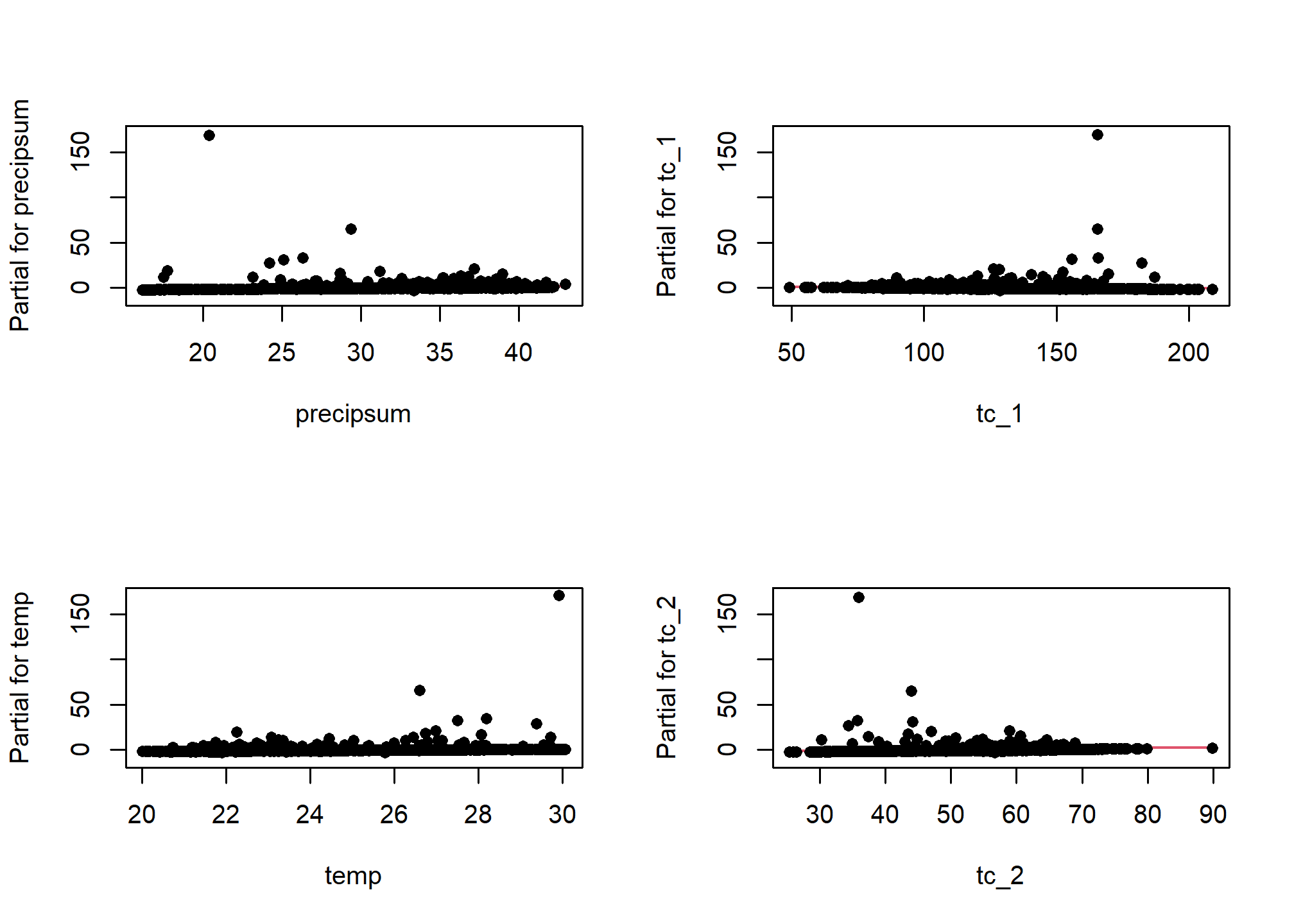
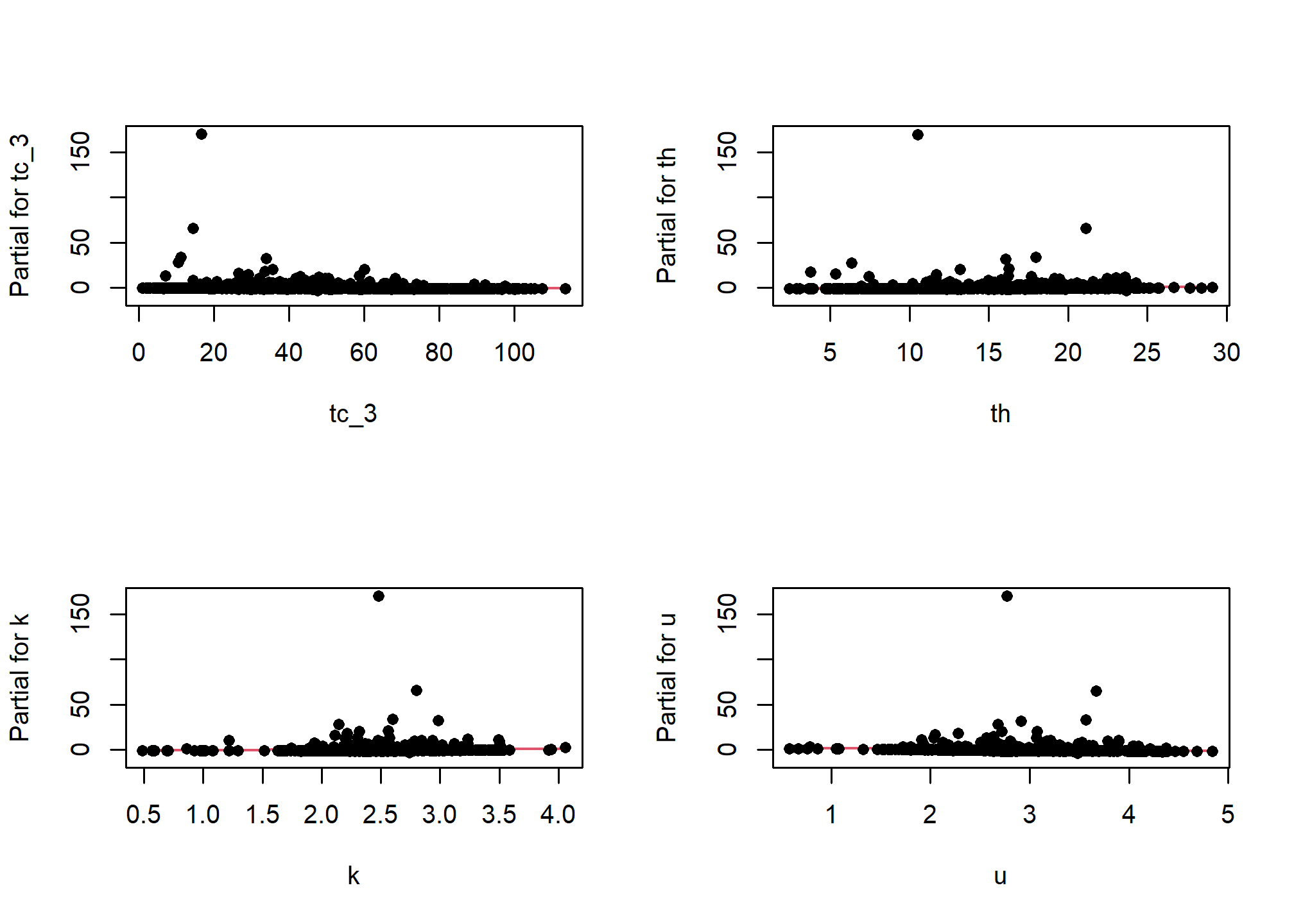
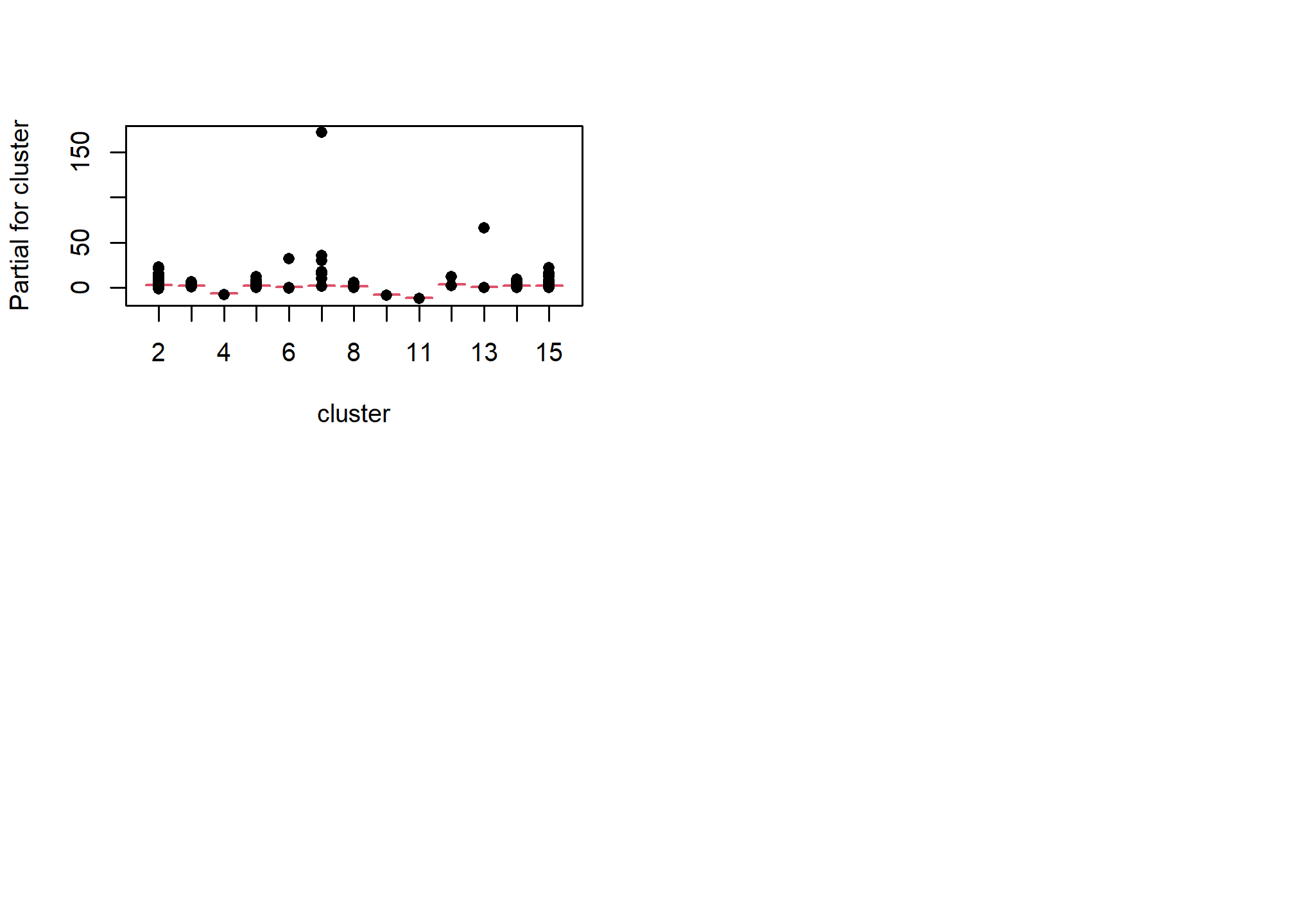
5.7.1.2 Multicolinearity
As we mentioned earlier multicolinearity should be avoided. To assess a model for multicolinearity we can compute the variance inflation factor (VIF). Its square root indicates the amount of increase in the predictor coefficients standard error. A value greater than 3 indicates a doubling the standard error. Rules of thumb vary, but a square root of vif greater than 2 or 3 indicates an unacceptable value.
5.7.2 Variable Selection & model validation
Modeling is an iterative process that cycles between fitting and evaluating alternative models. Compared to tree and forest models, linear and generalized models typically require more scrunity from the user. Automated model selection procedures are available, but should not be taken at face value because they may result in complex and unstable models. This is in part due to correlation amongst the predictive variables that can confuse the model. Also, the order in which the variables are included or excluded from the model effects the significance of the other variables, and thus several weak predictors might mask the effect of one strong predictor. Regardless of the approach used, variable selection is probably the most controversial aspect of linear modeling.
Both the rms and caret packages offer methods for variable selection and cross-validation. In this instance the rms approach is a bit more convinent and faster, with the one line call to validate().
The results for validate() above show which variables were retained and deleted. Below we can see a dot matrix of which variables were retained in during the 40 iterations of the bootstrapping. In addition, below we can see the difference between the training and test accuracy and error metrics. Remember that it is the test accuracy we should pay attention too.
5.7.3 Final model & accuracy
Once we’ve settled on a final model we can fit it and validate it. The validate() function can also be used for cross-validation and will get multiple probability-based accuracy metrics, including: \(R^2\), the Brier score (B), Tjur’s D (D), and many others.
final_lrm <- lrm(argillic ~ slp + twi_sc + tc_1 + tc_2 + precipsum, data = train, x = TRUE, y = TRUE)
validate(final_lrm, method = "crossvalidation", B = 10)## index.orig training test optimism index.corrected Lower Upper
## Dxy 0.7068 0.7070 0.6921 0.0149 0.6919 0.4357 0.9356
## R2 0.3202 0.3211 0.3148 0.0063 0.3139 0.1175 0.6075
## Intercept 0.0000 0.0000 -0.0920 0.0920 -0.0920 -1.4386 1.2852
## Slope 1.0000 1.0000 0.9989 0.0011 0.9989 0.1373 1.9103
## Emax 0.0000 0.0000 0.1485 -0.1485 0.1485 -0.0134 0.3714
## D 0.1684 0.1688 0.1565 0.0124 0.1560 0.0148 0.3666
## U -0.0017 -0.0019 -0.0007 -0.0012 -0.0005 -0.0259 0.0407
## Q 0.1701 0.1708 0.1571 0.0136 0.1565 -0.0094 0.3808
## B 0.0755 0.0754 0.0768 -0.0013 0.0768 -0.0094 0.1045
## g 3.7232 3.7428 3.6848 0.0579 3.6653 0.6643 6.6808
## gp 0.1311 0.1312 0.1275 0.0037 0.1273 0.0212 0.2170
## n
## Dxy 10
## R2 10
## Intercept 10
## Slope 10
## Emax 10
## D 10
## U 10
## Q 10
## B 10
## g 10
## gp 10# Compare the metrics from rms::validate() to aqp::brierScore() and modEvA::RsqGLM()
pred <- predict(final_lrm, train, type = "fitted")
test <- data.frame(pred, obs = train$argillic == "yes")
# Brier score
brierScore(test, classLabels = "pred", actual = "obs")## [1] 0.07219881## CoxSnell Nagelkerke McFadden Tjur sqPearson
## 0.1557253 0.3201934 0.2540906 0.1842274 0.1879082Because we’re dealing with a classification problem, we have to consider both errors of commission (Type I) and omission (Type II), or their corresponding accuracies of sensitivity and positive predicted value respectively. Before we can assess the error, however, we need to select a probability threshold.
- Sensitivity and specificity examine how well the ground truth or reference data compares to the predictions.
- Positive and negative predicted values examine the inverse concept of how well the predictions match the reference data as a function of their prevalence (see
help(confusionMatrix).
# examine possible thresholds
ggplot(test, aes(x = pred, fill = obs)) +
geom_density(alpha = 0.5) +
geom_vline(aes(xintercept = 0.5), lty = "dashed") +
xlab("probability") +
scale_x_continuous(breaks = seq(0, 1, 0.2))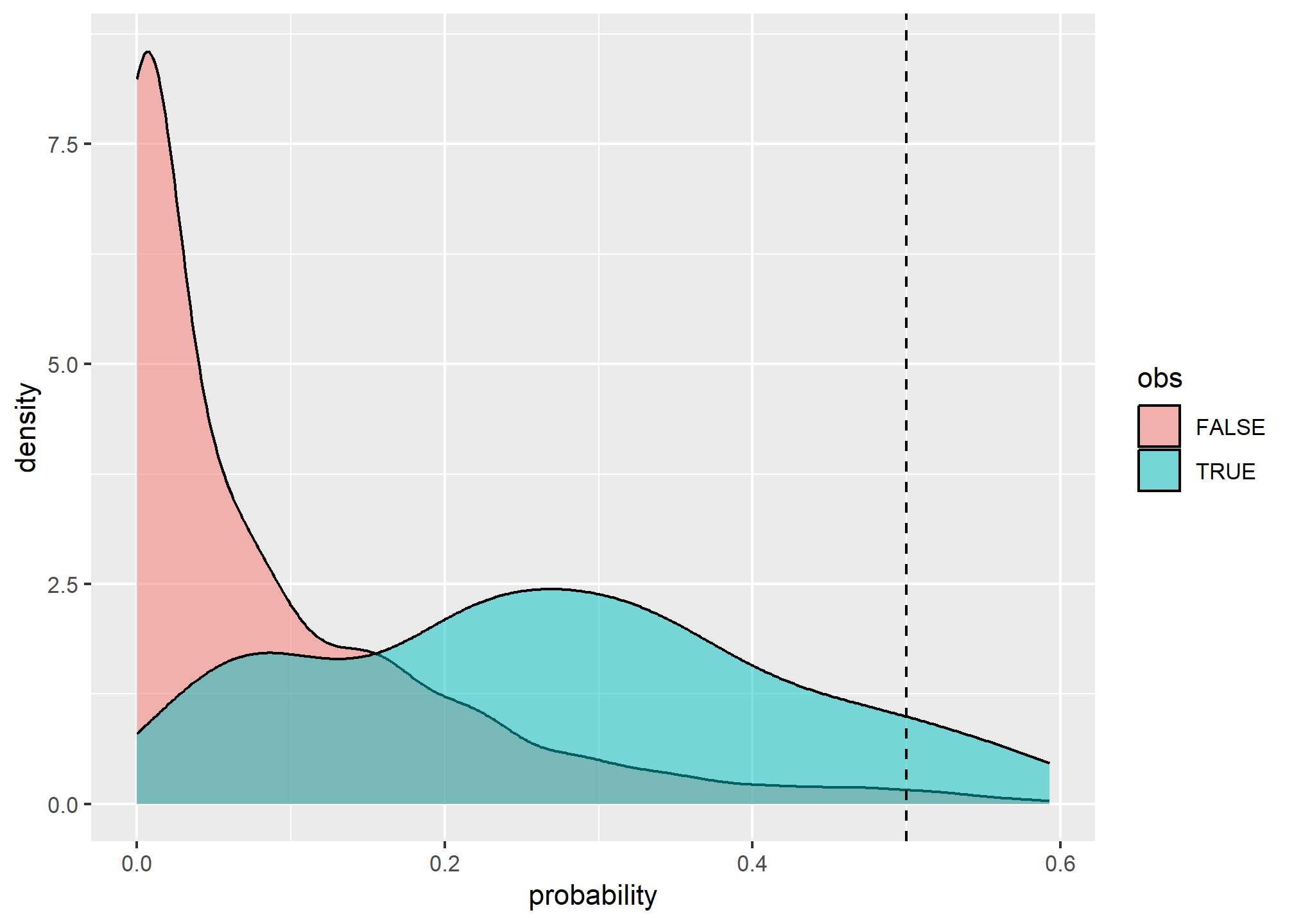
test$predictedClass <- ifelse(test$pred > 0.25, TRUE, FALSE)
# Confusion Matrix
cm <- table(predicted = test$predictedClass, observed = test$obs)
confusionMatrix(cm, positive = "TRUE")## Confusion Matrix and Statistics
##
## observed
## predicted FALSE TRUE
## FALSE 954 56
## TRUE 92 65
##
## Accuracy : 0.8732
## 95% CI : (0.8527, 0.8917)
## No Information Rate : 0.8963
## P-Value [Acc > NIR] : 0.994946
##
## Kappa : 0.397
##
## Mcnemar's Test P-Value : 0.004015
##
## Sensitivity : 0.5372
## Specificity : 0.9120
## Pos Pred Value : 0.4140
## Neg Pred Value : 0.9446
## Prevalence : 0.1037
## Detection Rate : 0.0557
## Detection Prevalence : 0.1345
## Balanced Accuracy : 0.7246
##
## 'Positive' Class : TRUE
## # Spatially variable accuracy
test$cluster <- train$cluster
temp <- test %>%
group_by(cluster) %>%
summarise(
TP = sum(predictedClass == TRUE & obs, na.rm = TRUE),
FN = sum(predictedClass == FALSE & obs, na.rm = TRUE),
sensitivity = TP / (TP + FN),
n = length(obs)
)
ggplot(temp, aes(x = cluster, y = sensitivity, size = n)) +
geom_point()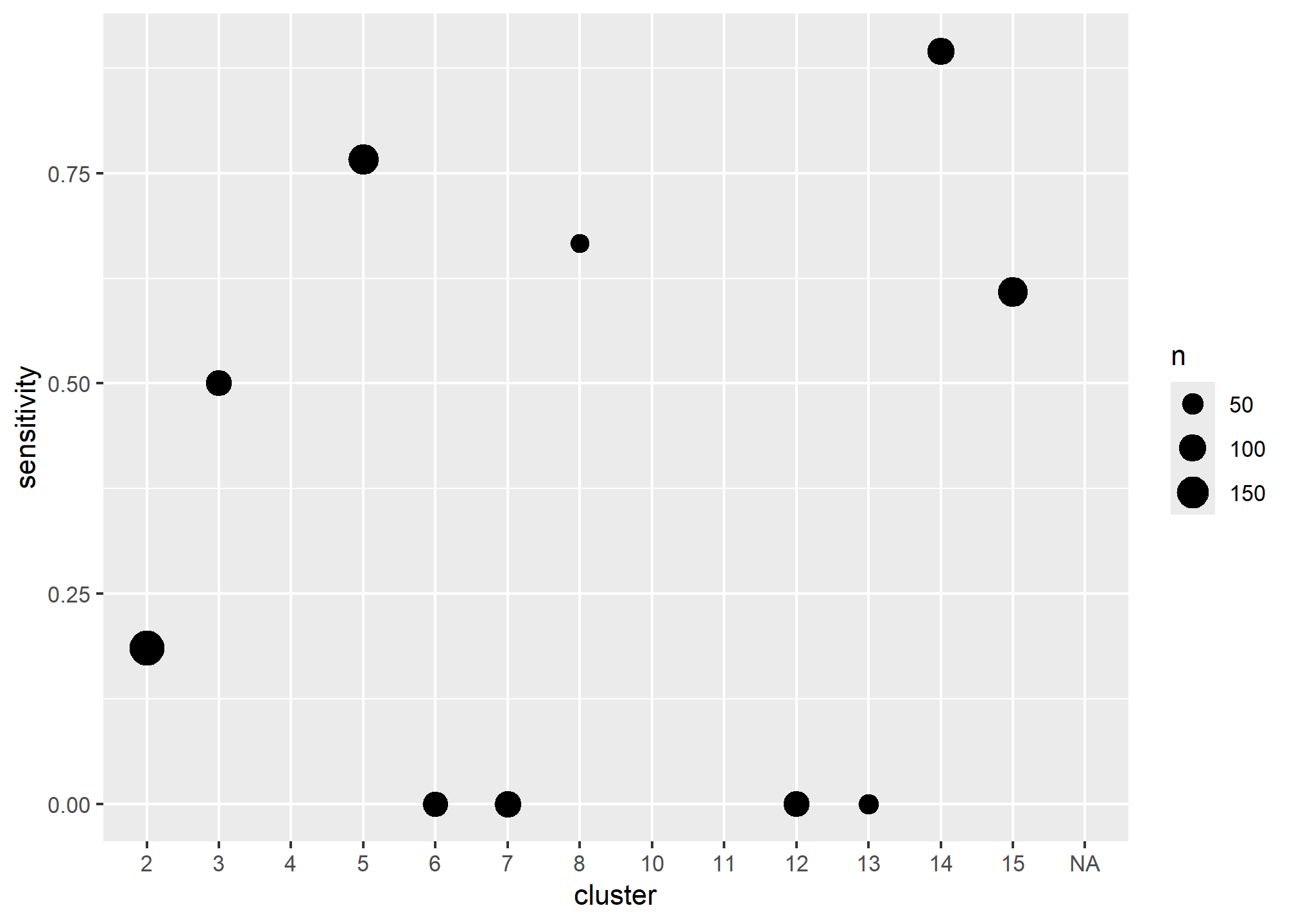
- Discuss the variability of the predictions across the clusters, perhaps different models need to be constructed in each cluster, some clusters appear to be dominated by specific soil series, these data aren’t clean enough (nor are the series concepts usually) to model series separately, however, we could use the clusters as an additional model to attempt to separate the series. Do the hyperthermic clusters perform differently.
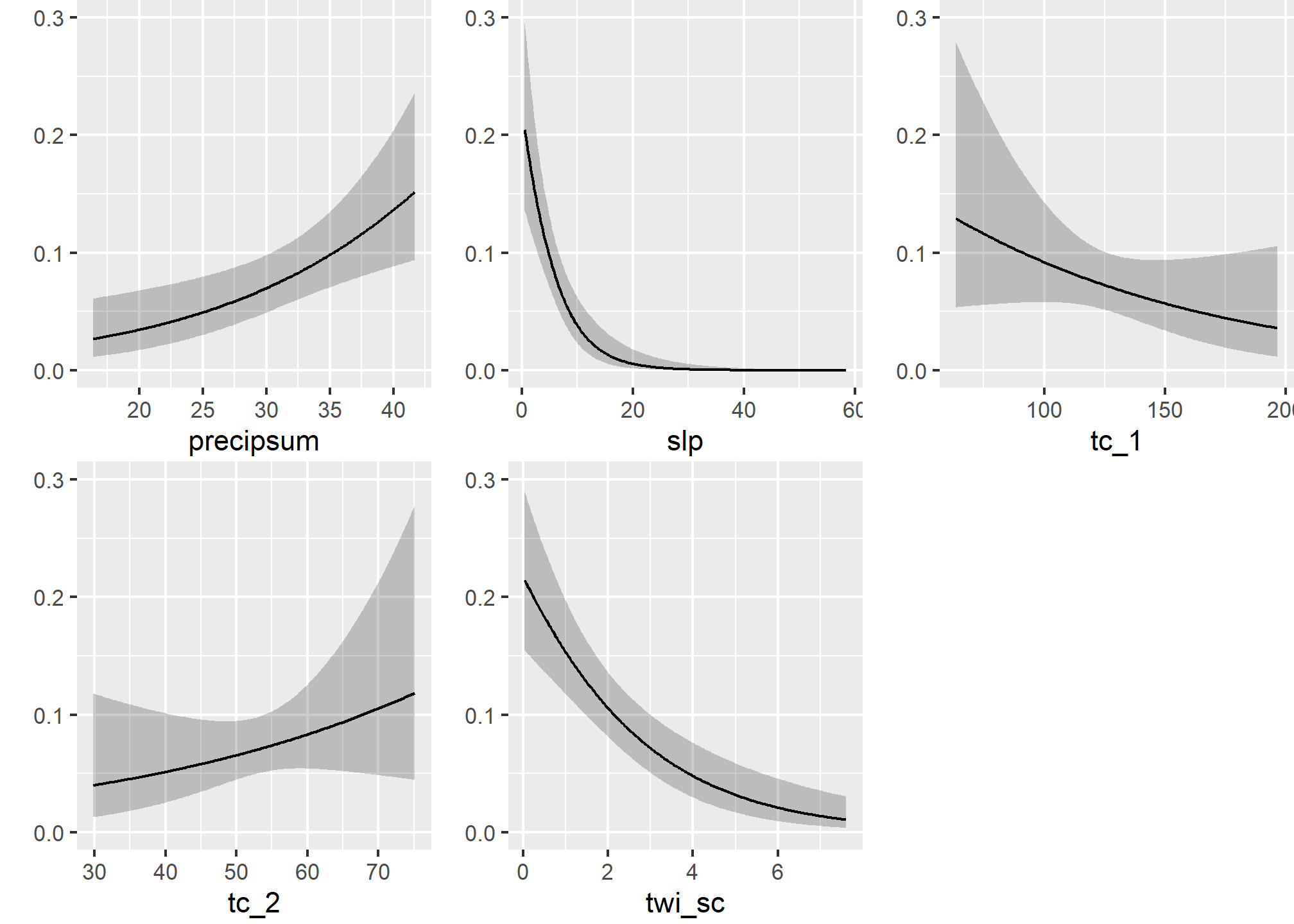
5.7.4 Model effects
## Frequencies of Missing Values Due to Each Variable
## argillic slp twi_sc tc_1 tc_2 precipsum
## 8 52 53 52 52 52
##
## Logistic Regression Model
##
## lrm(formula = argillic ~ slp + twi_sc + tc_1 + tc_2 + precipsum,
## data = train, x = TRUE, y = TRUE)
##
##
## Model Likelihood Discrimination Rank Discrim.
## Ratio Test Indexes Indexes
## Obs 1167 LR chi2 197.55 R2 0.320 C 0.853
## no 1046 d.f. 5 R2(5,1167)0.152 Dxy 0.707
## yes 121 Pr(> chi2) <0.0001 R2(5,325.4)0.447 gamma 0.707
## max |deriv| 0.0004 Brier 0.075 tau-a 0.131
##
## Coef S.E. Wald Z Pr(>|Z|)
## Intercept -2.3859 1.8877 -1.26 0.2062
## slp -0.1968 0.0394 -5.00 <0.0001
## twi_sc -0.4272 0.0887 -4.82 <0.0001
## tc_1 -0.0104 0.0076 -1.36 0.1730
## tc_2 0.0259 0.0237 1.09 0.2748
## precipsum 0.0743 0.0247 3.01 0.0026## Wald Statistics Response: argillic
##
## Factor Chi-Square d.f. P
## slp 24.97 1 <.0001
## twi_sc 23.20 1 <.0001
## tc_1 1.86 1 0.1730
## tc_2 1.19 1 0.2748
## precipsum 9.06 1 0.0026
## TOTAL 85.86 5 <.0001## Effects Response : argillic
##
## Factor Low High Diff. Effect S.E. Lower 0.95 Upper 0.95
## slp 3.5798 24.4420 20.8620 -4.106300 0.82180 -5.7170000 -2.495700
## Odds Ratio 3.5798 24.4420 20.8620 0.016468 NA 0.0032895 0.082443
## twi_sc 1.3002 4.6222 3.3219 -1.419100 0.29461 -1.9966000 -0.841720
## Odds Ratio 1.3002 4.6222 3.3219 0.241920 NA 0.1358000 0.430970
## tc_1 103.6200 144.7600 41.1350 -0.427900 0.31405 -1.0434000 0.187630
## Odds Ratio 103.6200 144.7600 41.1350 0.651880 NA 0.3522400 1.206400
## tc_2 46.3230 60.8050 14.4820 0.374410 0.34284 -0.2975500 1.046400
## Odds Ratio 46.3230 60.8050 14.4820 1.454100 NA 0.7426400 2.847300
## precipsum 26.4350 35.6600 9.2253 0.685080 0.22765 0.2388900 1.131300
## Odds Ratio 26.4350 35.6600 9.2253 1.983900 NA 1.2698000 3.099600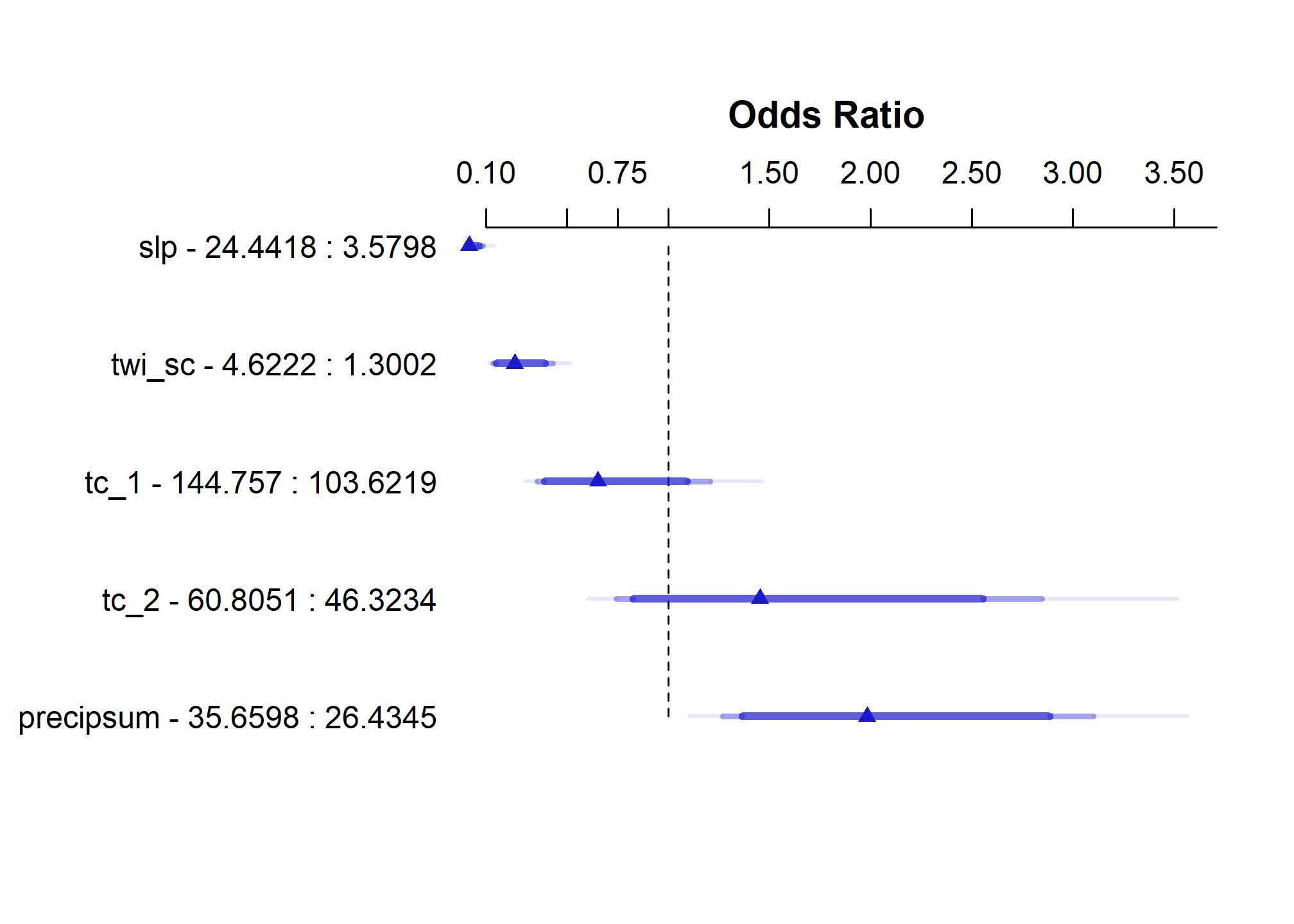
- View the results in ArcGIS and examine the accuracy at individual points
- Discuss the effects of data quality, including both NASIS and GIS
- Discuss how the modeling process isn’t an end in itself, but serves to uncover trends, possibly generate additional questions and direct future investigations
5.8 Generate spatial predictions
# Custom function to return the predictions and their standard errors
library(raster)
# wrapper function, to help with prediction at each grid cell
predfun <- function(model, data) {
# predict presence of argillic horizon (outcome = TRUE)
# result is vector of probabilities
prob <- predict(model, data, type = "fitted")
# compute Shannon entropy from both (FALSE | TRUE) probabilities
H <- apply(cbind(prob, 1 - prob), 1, shannonEntropy)
# combine Pr(Argillic == TRUE) and Shannon entropy
res <- cbind(prob, H)
# return to calling function
return(res)
}
# Generate spatial predictions
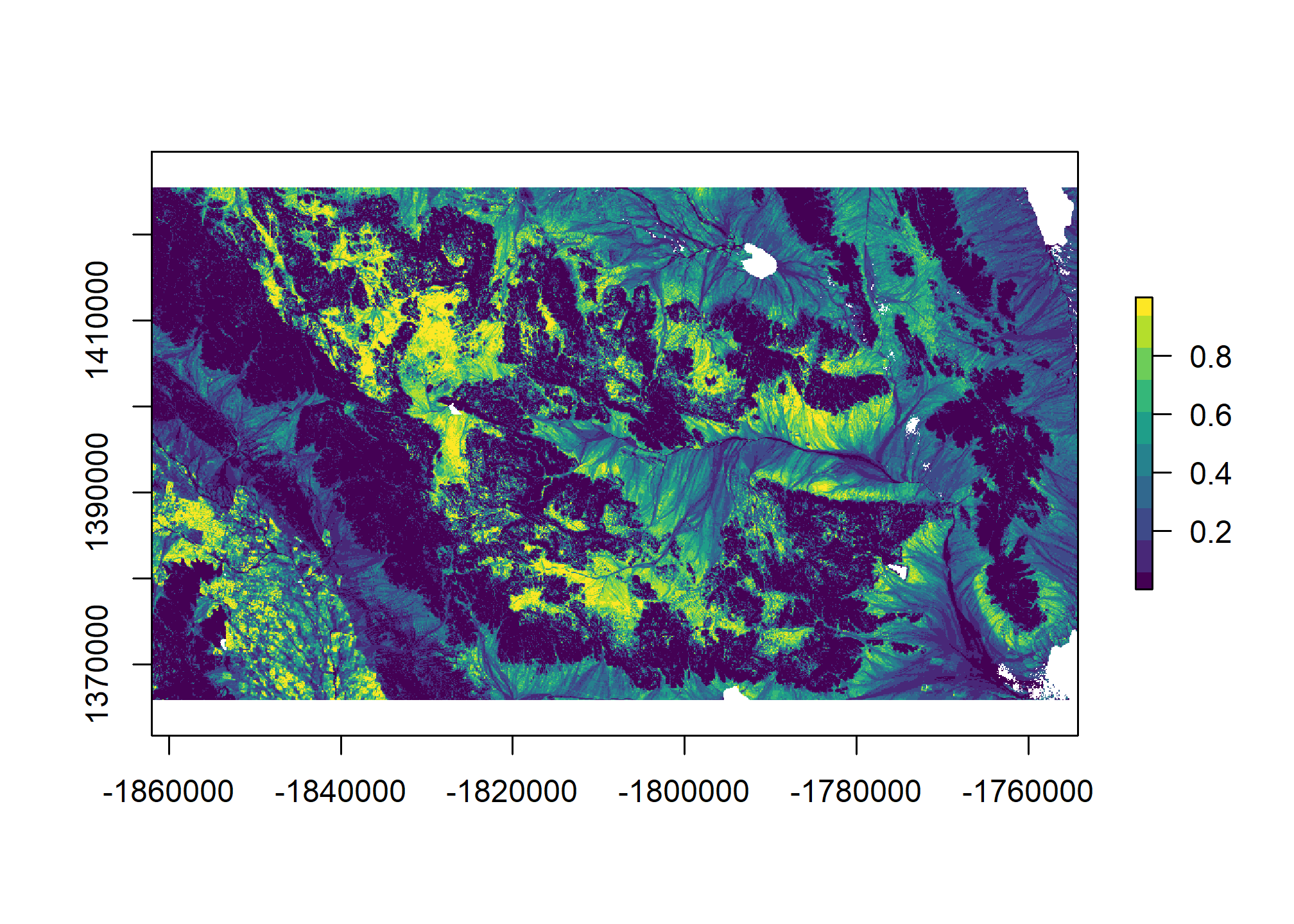
r <- predict(geodata_r, final_lrm, fun = predfun, index = 1:2, progress = "text")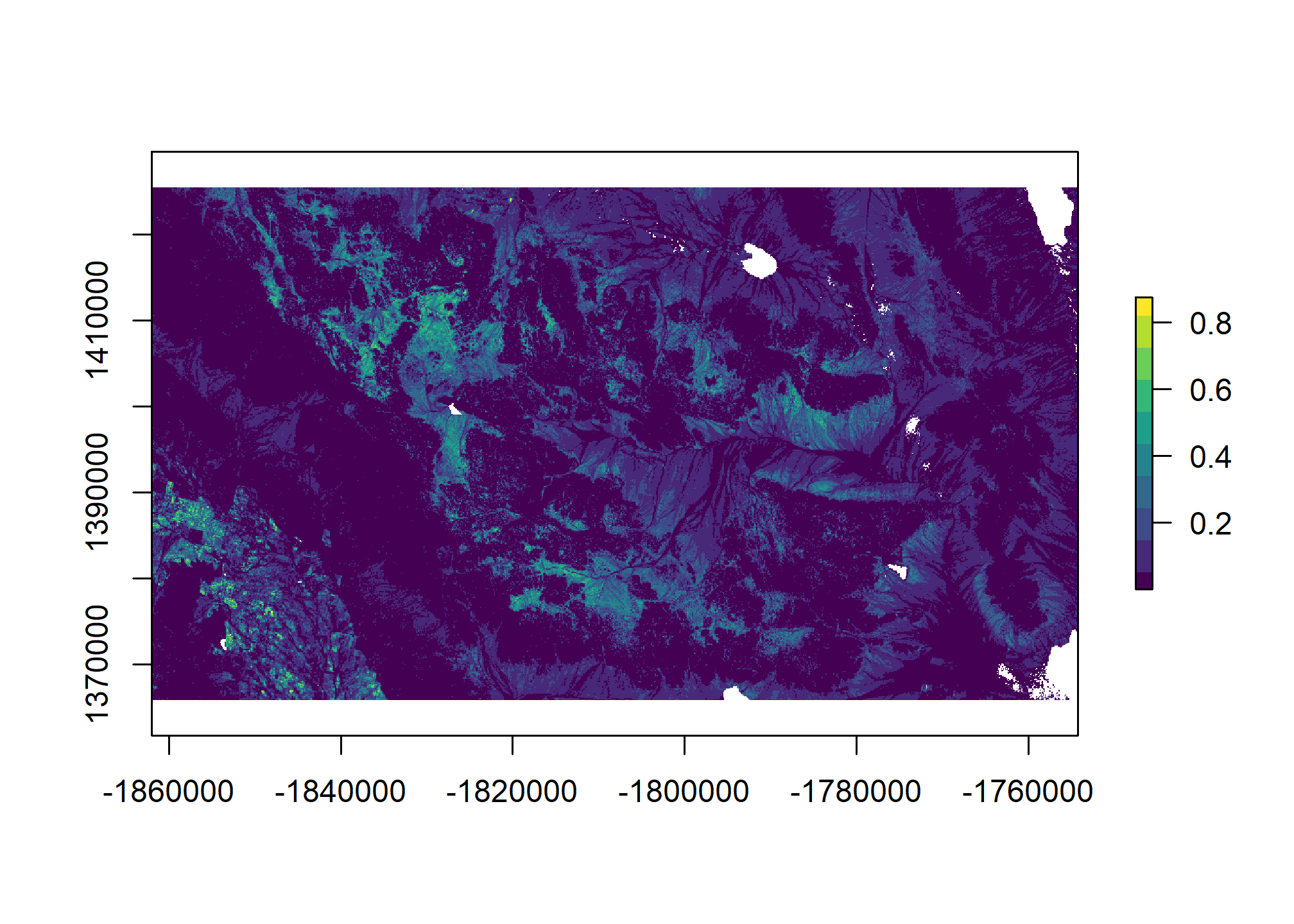
5.9 Exercise
- Construct a dataset of shallow soils as shown below.
URL <- url("https://raw.githubusercontent.com/ncss-tech/stats_for_soil_survey/master/data/ch7_data.Rdata")
load(URL)
train2 <- aqp::allocate(pedons, to = "ST Diagnostic Features")
train2 <- train2 %>%
mutate(shallow = grepl("contact", train2$featkind) & train2$featdept) %>%
arrange(peiid, -shallow, featdept) %>%
filter(shallow == TRUE & ! duplicated(peiid)) %>%
right_join(data, by = "peiid") %>%
mutate(shallow = ifelse(is.na(shallow), FALSE, shallow)) %>%
select(z:mast, pc_1:u, ndvi:gsi, shallow)Fit a GLM
Perform a variable selection
- Does the automatic selection make sense?
Assess the model accuracy and plot the fit
- How do the train vs test accuracies compare?
Summarize and plot the model effects
- Which variable has the steepest slope?
- Which variable has the greatest effect?
- Which variable has the highest Chi-squared?
5.10 Additional reading
The application of generalized linear models in soil science are described by Lane (2002).@james2021 provide a useful introduction to logistic regression.