Chapter 1 Introduction to R
![]()
1.1 Outline
- Course Overview
- Review Course Objectives
- Why is this training needed?
- Why is course organized this way?
- What is R?
- Why should I use R?
- What can R do?
- How do I get started?
- RStudio interface
- What are packages?
- How to navigate the Help tab
- How to save files
- Manipulating data
- Loading & viewing data
- Filtering, transforming, merging, aggregating and reshaping data
- Exporting data
1.2 Course Overview
1.2.1 Course Objectives
- Develop solutions to investigate soil survey correlation problems and update activities.
- Evaluate investigations for interpretive results and determine how to proceed.
- Summarize data for population in NASIS.
- Analyze spatial data to investigate soil-landscape relationships
- Help to pursue the question “why”
1.2.2 Why is this training needed?
- Long standing goal of the Soil Science Division to have a course in statistics (Mausbach 2003)
- Opportunities to learn these techniques are limited, especially at the undergraduate level (Hennemann and Rossiter 2004)
- Consistent methodology (data analysis, data population, sampling design, etc.)
- There is continually a greater need to use these techniques:
- Mapping of lands at high production rates ((MacMillan, Moon, and Coupé 2007); (Kempen et al. 2012); (Brevik et al. 2016))
- Ecological Sites (Maynard et al. 2019)
- Soil survey refinement (disaggregation) ((Chaney et al. 2016);(Ramcharan et al. 2018))
1.2.3 Why is course organized this way?
- The web content is a long-term investment and serves as a reference
- Our best judgment for assembling into 24 hours what could be 6 University level courses
- Mixture of slides and script-enabled web pages is “new” for NRCS
Feel free to provide feedback for improving the class for future offerings.
1.3 What is R?
R is a free, open-source software and programming language developed in 1995 at the University of Auckland as an environment for statistical computing and graphics (Ihaka and Gentleman 1996). Since then R has become one of the dominant software environments for data analysis and is used by a variety of scientific disiplines, including soil science, ecology, and geoinformatics (Envirometrics CRAN Task View; Spatial CRAN Task View). R is particularly popular for its graphical capabilities, but it is also prized for it’s GIS capabilities which make it relatively easy to generate raster-based models. More recently, R has also gained several packages designed specifically for analyzing soil data.
- A software environment:
- statistics
- graphics
- programming
- calculator
- GIS
- A language to explore, summarize, and model data
- functions = verbs
- objects = nouns

1.3.1 Why Should I Learn R?
While the vast majority of people use Microsoft Excel for data analysis, R offers numerous advantages, such as:
Cost. R is free! (“Free as in free speech, not free beer.”)
Reproducible Research (self-documenting, repeatable)
- repeatable:
- code + output in a single document (‘I want the right answer, not a quick answer’ - Paul Finnell)
- easier the next time (humorous example)
- numerous Excel horror stories of scientific studies gone wrong exist (TED Talk)
- scalable: applicable to small or large problems
- repeatable:
R in a Community
Learning Resources (quantity and quality)
“If we don’t accept these challenges, others who are less qualified will; and soil scientists will be displaced by apathy.” (Arnold and Wilding 1991)
While some people find the use of a command line environment daunting, it is becoming a necessary skill for scientists as the volume and variety of data has grown. Thus scripting or programming has become a third language for many scientists, in addition to their native language and discipline specific terminology. Other popular programming languages include: SQL (i.e. NASIS), Python (i.e. ArcGIS), and JavaScript.
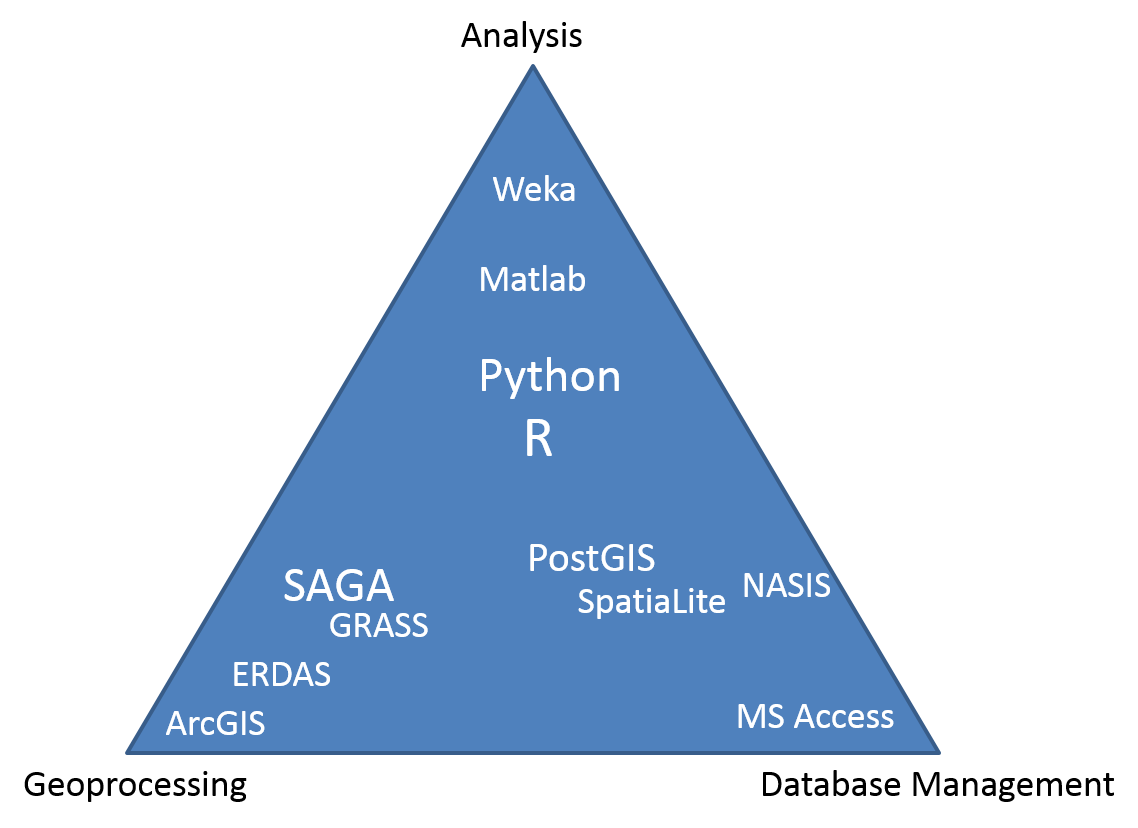
1.3.3 Packages
- Base R (functionality is extended through packages)
- basic summaries of quantitative or qualitative data
- data exploration via graphics
- GIS data processing and analysis
- Soil Science R Packages
- aqp - visualization, aggregation, classification
- soilDB - access to commonly used soil databases
- soilReports - handful of report templates
- soiltexture - textural triangles
- Ecology R packages
1.4 RStudio: An Integrated Development Environment (IDE) for R
RStudio is an integrated development environment (IDE) that allows you to interact with R more readily. RStudio is similar to the standard RGui, but is considerably more user friendly. It has more drop-down menus, windows with multiple tabs, and many customization options. The first time you open RStudio, you will see three windows. A forth window is hidden by default, but can be opened by clicking the File drop-down menu, then New File, and then R Script. Detailed information on using RStudio can be found at at RStudio’s Website.
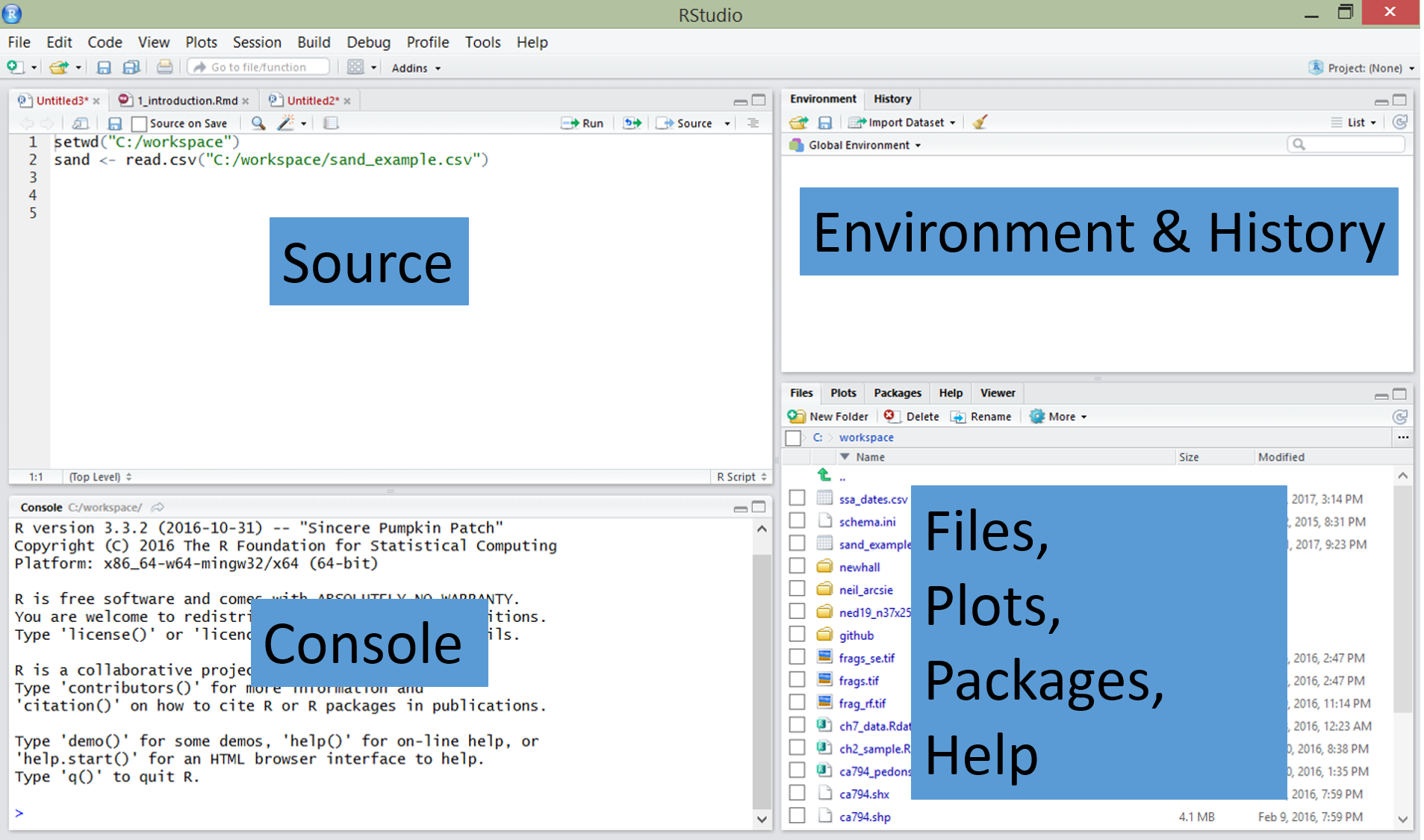
| RStudio Windows / Tabs | Location | Description |
|---|---|---|
| Console Window | lower-left | location were commands are entered and the output is printed |
| Source Tabs | upper-left | built-in text editor |
| Environment Tab | upper-right | interactive list of loaded R objects |
| History Tab | upper-right | list of key strokes entered into the Console |
| Files Tab | lower-right | file explorer to navigate C drive folders |
| Plots Tab | lower-right | output location for plots |
| Packages Tab | lower-right | list of installed packages |
| Help Tab | lower-right | output location for help commands and help search window |
| Viewer Tab | lower-right | advanced tab for local web content |
1.5 R basics
R is command-line driven. It requires you to type or copy-and-paste commands after a command prompt (>) that appears when you open R. This is called the “Read-Eval-Print-Loop” or REPL. After typing a command in the R console and pressing Enter on your keyboard, the command will run.
If your command is not complete, R issues a continuation prompt (signified by a plus sign:
+).R is case sensitive. Make sure your spelling and capitalization are correct.
Commands in R are also called functions. The basic format of a function in R is:
object <- function.name(argument_1 = data, argument_2 = TRUE).The up arrow (^) on your keyboard can be used to bring up previous commands that you’ve typed in the R console.
Comments in R code need to start with the
#symbol (a.k.a. hash-tag, comment, pound, or number symbol). R ignores the remainder of the script line following#.
# Math
1 + 1
10 * 10
log10(100)
# combine values
c(1, 2, 3)
# Create sequence of values
1:10
# Implicit looping
1:10 * 5
1:10 * 1:10
# Assignment and data types
## numeric
clay <- c(10, 12, 15, 26, 30)
## character
subgroup <- c("typic haplocryepts","andic haplocryepts","typic dystrocryepts")
## logical
andic <- c(FALSE, TRUE ,FALSE)
# Print
print(clay)
subgroup1.6 Managing Packages
Packages are collections of additional functions that can be loaded on demand. They commonly include example data that can be used to demonstrate those functions. Although R comes with many common statistical functions and models, most of our work requires additional packages.
1.6.1 Installing Packages
To use a package, you must first install it and then load it. These steps can be done at the command line or using the Packages Tab. Examples of both approaches are provided below. R packages only need to be installed once (until R is upgraded or re-installed). Every time you start a new R session, however, you need to load every package that you intend to use in that session.
Within the Packages tab you will see a list of all the packages currently installed on your computer, and 2 buttons labeled either “Install” or “Update”. To install a new package simply select the Install button. You can enter install one or more than one packages at a time by simply separating them with a comma.
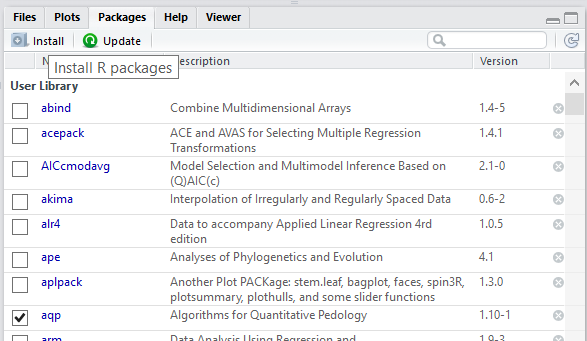
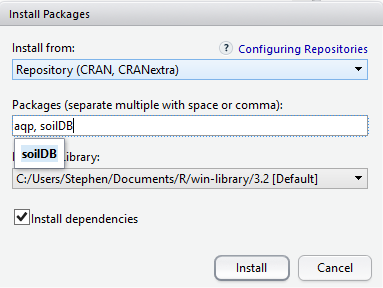
To find out what packages are installed on your computer, use the following commands:
One useful package for soil scientists is the soiltexture package. It allows you to plot soil textural triangles. The following command shows how to install this package if you do not currently have it downloaded:
1.6.2 Loading Packages
Once a package is installed, it must be loaded into the R session to be used. This can be done by using library(). The package name does not need to be quoted.
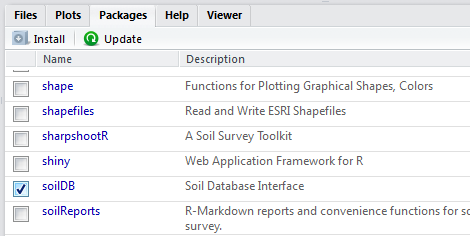
You can also load packages using the Packages Tab, by checking the box next to the package name. For example, documentation for the soilDB package is available from the help() function.
1.7 Getting Help
R has extensive documentation, numerous mailing lists, and countless books (many of which are free and listed at end of each chapter for this course).
To learn more about the function you are using and the options and arguments available, learn to help yourself by taking advantage of some of the following help functions in RStudio:
- Use the Help tab in the lower-right Window to search commands (such as hist) or topics (such as histogram).
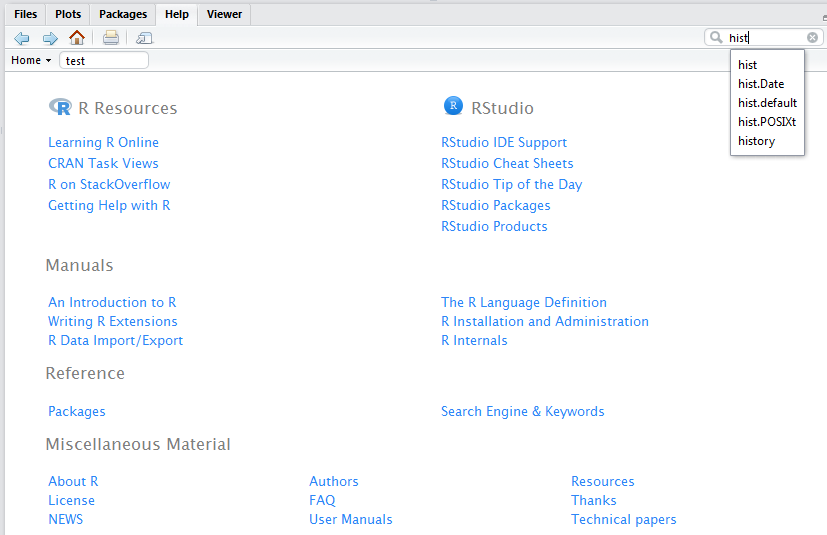
- Type
help(read.csv) or ?read.csvin the Console window to bring up a help page. Results will appear in the Help tab in the lower right-hand window. Certain functions may require quotations, such ashelp("+").
1.8 Documenting your work
RStudio’s Source Tabs serve as a built-in text editor. Prior to executing R functions at the Console, commands are typically written down (or scripted). Scripting is essentially showing your work.
The sequence of functions necessary to complete a task are scripted in order to document or automate a task.
While scripting may seems cumbersome at first, it ultimately saves time in the long run, particularly for repetitive tasks (humorous YouTube Video on Scripting).
Benefits include:
- allows others to reproduce your work, which is the foundation of science
- serves as instruction/reminder on how to perform a task
- allows rapid iteration, which saves time and allows the evaluation of incremental changes
- reduces the chance of human error
1.8.1 Basic Tips for Scripting
To write a script, simply open a new R script file by clicking File>New File>R Script. Within the text editor type out a sequence of functions.
- Place each function (e.g.
read.csv()) on a separate line. - If a function has a long list of arguments, place each argument on a separate line.
- A command can be excuted from the text editor by placing the cursor on a line and typing Crtl + Enter, or by clicking the Run button.
- An entire R script file can be excuted by clicking the Source button.
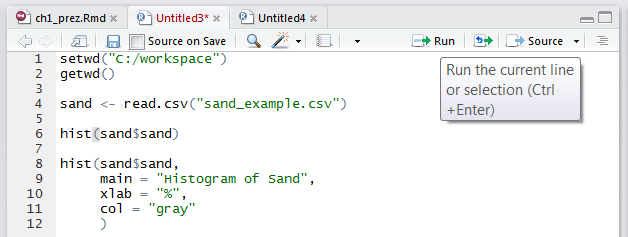
1.9 Organizing your work
When you first begin a project you should create a new folder and place within it all the data and code associated with the project. This simplifies the process of accessing your files from R. Using a project folder is also a good habit because it makes it easier to pickup where you left off and find your data if you need to come back to it later. Within R, your project folder is also known as your working directory. This directory will be the default location your plots and other R output are saved.
You want to have inputs for your code in the working directory so that you can refer to them using relative file paths. Relative file paths make it easier if you move the folder containing your script(s) around. Or, if you share it with someone else, they will have little issue getting your code to work on their own file system.
1.9.1 Setting the Working Directory
Before you begin working in R, you should set your working directory to your project folder; for example, setwd("C:\\workspace2\\projectx..."). You can use RStudio to manage your projects and folders.
NOTE: Beware when specifying any file paths that R uses forward slashes / instead of back slashes \. Back slashes are reserved for use as an escape character, so you must use two of them to get one in result character string.
To change the working directory in RStudio, select main menu Session >> Set Working Directory >> …. Or, from the “Files” tab click More >> Set As Working Directory to use the current location of the “Files” tab as your working directory.
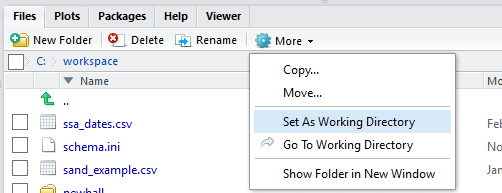
Setting the working directory can also be done via the Console with the setwd() command:
To check the file path of the current working directory (which should now be "C:\\workspace2"), type:
1.9.2 RStudio Projects (.Rproj files)
You can also manage your working directory using RStudio Projects. An RStudio Project file (.Rproj) is analogous to, for example, a .mxd file for ArcMap. It contains information about the specific settings you may have set for a “project”.
You open or create projects using the drop down menu in the top right-hand corner of the RStudio window (shown below)

Here is what a typical Project drop-down menu looks like:
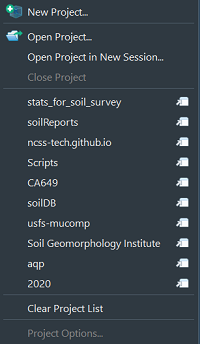
You can create new projects from existing or new directories with “New Project…”.
When you click “Open Project…”, your working directory is automatically set to the .Rproj file’s location – this is extremely handy
Any projects you have created/used recently will show up in the “Project List”
1.10 Saving your work
In R, you can save several types of files to keep track of the work you do. The file types include: workspace, script, history, and graphics. It is important to save often because R, like any other software, may crash periodically.
Such problems are especially likely when working with large files. You can save your workspace in R via the command line or the File menu.
1.10.0.1 R script (.R)
An R script is simply a text file of R commands that you’ve typed.
You may want to save your scripts (whether they were written in R Editor or another program such as Notepad) so that you can reference them in the future, edit them as needed, and keep track of what you’ve done.
To save R scripts in RStudio, simply click the save button from your R script tab. Save scripts with the .R extension.
R assumes that script files are saved with only that extension. If you are using another text editor, you won’t need to worry about saving your scripts in R. You can open text files in the RStudio text editor, but beware copying and pasting from Word files as discussed below.
To open an R script, click the file icon.
![]()
1.10.0.2 Microsoft Word Files
Using Microsoft Word to write or save R scripts is generally a bad idea.
Certain keyboard characters, such as quotations ““, are not stored the same in Word (e.g. they are”left” and “right” handed). The difference is hard to distinguish, but will not run in R.
Also, pasting your R code or output into Word documents manually is not reproducible, so while it may work in a pinch, it ultimately costs you time.
You can use the word_document Rmarkdown template to automatically “Knit” .docx files from R code using a template, which is very handy for quickly getting a nice looking document!
1.10.0.3 R Markdown (.Rmd)
R Markdown (.Rmd) documents contain information for the reproducible combination of narrative text and code to produce elegantly formatted output. You can use multiple languages in .Rmd documents including R, Python, and SQL. You can easily “knit” visually appealing and high-quality documents into rich HTML, PDF or Word documents from the RStudio interface.
The Statistics for Soil Survey webpage is made in bookdown, which is a variant of rmarkdown used for book templates with multiple chapters. You can make blogs and websites for your R packages with blogdown and pkgdown. These are all tools based off of the powerful “pandoc” engine and the tools in the R Markdown ecosystem.
1.10.0.4 R history (.Rhistory)
An R history file is a copy of all your key strokes. You can think of it as brute force way of saving your work. It can be useful if you didn’t document all your steps in an R script file.
Like an R file, an Rhistory file is simply a text file that lists all of the commands that you’ve executed. It does not keep a record of the results.
To load or save your R history from the History Tab click the Open File or Save button. If you load an Rhistory file, your previous commands will again become available with the up-arrow and down-arrow keys.
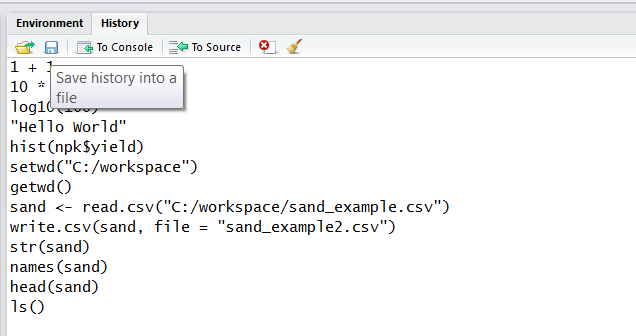
You can also use the command line to load or save your history.
1.10.0.5 R Graphics
Graphic outputs can be saved in various formats.
| Format | Function |
|---|---|
| pdf(“graphic.pdf”) | |
| window metafile | win.metafile(“graphic.wmf”) |
| png | png(“graph.png”) |
| jpeg | jpeg(“graph.jpg”) |
| bmp | bmp(“graph.bmp”) |
| postscript | postscript(“graph.ps”) |
To save a graphic: (1) Click the Plots Tab window, (2) click the Export button, (3) Choose your desired format, (3) Modify the export settings as you desire, and (4) click Save.
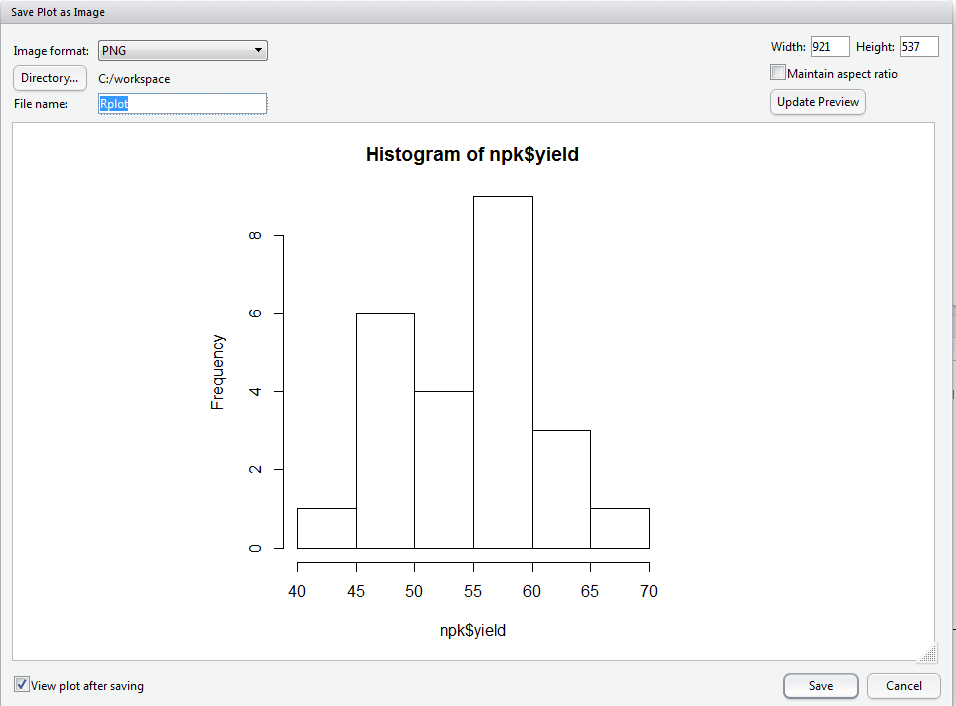
The R command for saving a graphic is:
The first line of this command creates a blank file named "npk_yield.png". The second line plots the data object that you want to create a graphic of (here it is conveniently the same name as the PNG file we are creating). The third line closes the graphics device.
Exercise 1: R packages and Functions
Using the examples discussed thus far as a guide, demonstrate your mastery of the material by performing the following tasks.
- Create a new R script file with all commands you use.
- Demonstrate usage of 3 R functions and comment (
#) your code with answers to the questions. - Install the FedData R package from CRAN and GitHub.
- Load the FedData R package and read the help file for the
get_ssurgo()function within the FedData package. What is the 1st input/argument? - Save your R script and forward to your mentor.
1.11 Loading Data
R can load a variety of data formats, however tabular data is by far the most common, and what we will spend of the majority of our time working with. Typically tabular data is stored in spreadsheets (e.g. .txt, .csv, .xlsx), databases (e.g. NASIS), or webpages (.html). Within R tabular data is stored as a data.frame.
1.11.0.1 Text files
Text files are a preferable format for storing and transferring small datasets. One basic command for importing text files into R is read.csv(). The command is followed by the file name or URL and then some optional instructions for how to read the file.
These files can either be imported into R by clicking the Import Dataset >> From Text buttons from the Environment tab, or by typing the following command into the R console:
# from URL
sand <- read.csv("https://raw.githubusercontent.com/ncss-tech/stats_for_soil_survey/master/data/sand_example.csv") 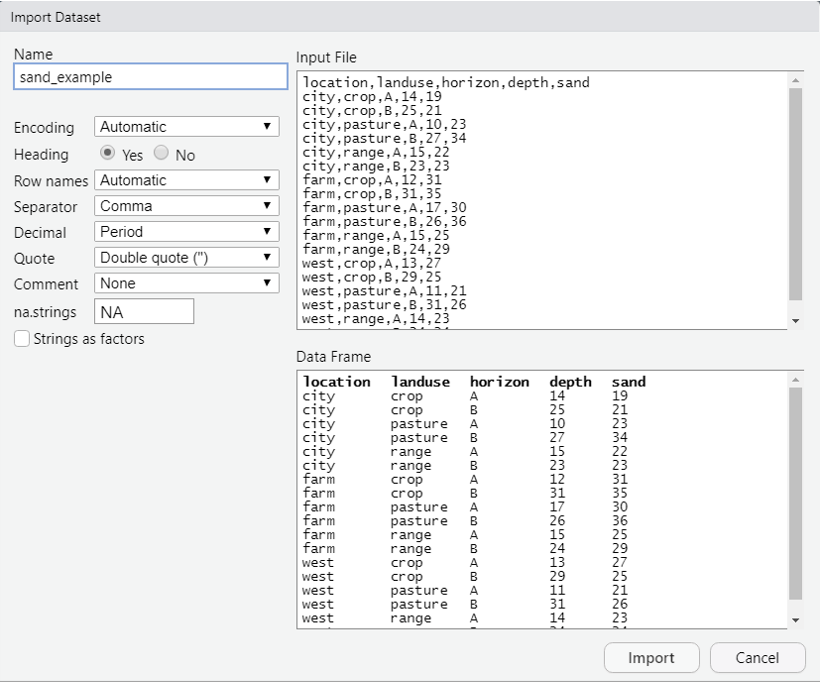
1.11.0.2 Excel files
R can import Excel files, but generally speaking it is a bad idea to use Excel. Excel has a dangerous default which automatically converts data with common notations to their standard format without warning or notice. For example, the character “11-JUN” entered into a cell automatically becomes the date 6/11/2021, even though the data is still displayed as 11-JUN. The only way to avoid this default behavior is to manually import your data into Excel via the Data Tab>Get External Data Ribbon, and manually set the data type of all your columns to text. Failure to do so has resulted in numerous retracted research articles (Washington Post Article). Warnings aside, Excel files are a very common and are a format most people are familiar with. Therefore we will illustrate how to bring them into R.
Download the sand Excel dataset from GitHub at https://github.com/ncss-tech/stats_for_soil_survey/raw/master/data/Pre-course/R_sand/sand_example.xlsx
Excel datasets can either be imported into R by clicking the Import Dataset >> From Excel buttons from the Environment tab, or by typing the following command into the R console:
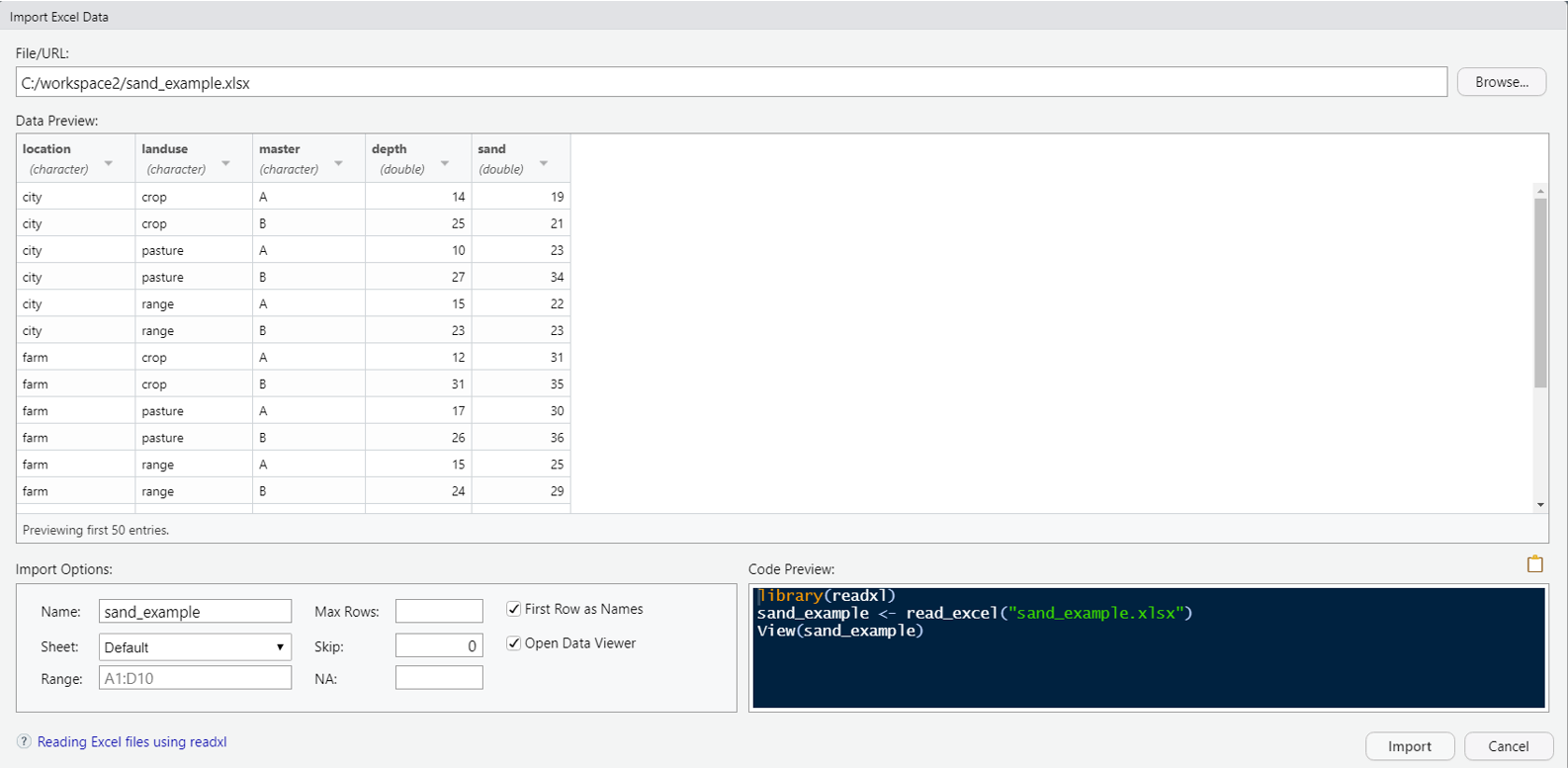
1.11.0.3 NASIS Web Reports
NASIS provides many reports that can be read into R for analysis. The soilDB R package provides a series of functions to read data from NASIS either using a local database connection or via HTML web reports. Similar functions also exist for accessing tabular data from Soil Data Access. More details on soilDB will be provided in the next chapter, but now we’ll illustrate how to access some example datasets for manipulating tabular data.
library(soilDB)
# get projects
prj <- get_project_from_NASISWebReport(mlrassoarea = "NE-IND", fiscalyear = 2020)
l# get legends
leg <- get_legend_from_NASISWebReport(mlraoffice = "Indi%", areasymbol = "%")
# get map units
mu <- get_mapunit_from_NASISWebReport(areasymbol = c("IN001", "IN11%"))Since these functions in soilDB query web reports, it is not necessary to be a NASIS user or set up your local database and selected set. We can simply pass parameters to the web report URL and get tabular results back.
1.12 Data manipulation
Before we can do any analysis our data usually needs to be manipulated one way or another. Estimates vary, but an analyst typically spend 80% of their time manipulating data and only 20% actually analyzing or modeling. Tasks generally involve filtering, transforming, merging, aggregating, and reshaping data.
R has many functions and packages for manipulating data frames, but within the past several years a family of packages, known as the tidyverse, have been developed to simplify interacting with data frames (or tibbles). Within the tidyverse the most commonly used packages are dplyr and tidyr. Many of the tidyverse function names are patterned after SQL functions. These packages and are built around the “tidy data” philosophy. This simply means that rows are observations and each column is a variable.
We will review the most common functions you need to know in order to accomplish the majority of data manipulation tasks.
1.12.1 Viewing and Removing Data
Once a file is imported, it is imperative that you check that R correctly imported your data. Make sure numeric data are correctly imported as numeric, that your column headings are preserved, etc. To view the data you can click on the mu dataset listed in the RStudio Environment tab. This will open up a separate window that displays a spreadsheet like view. This is equivalent to the function View(mu).
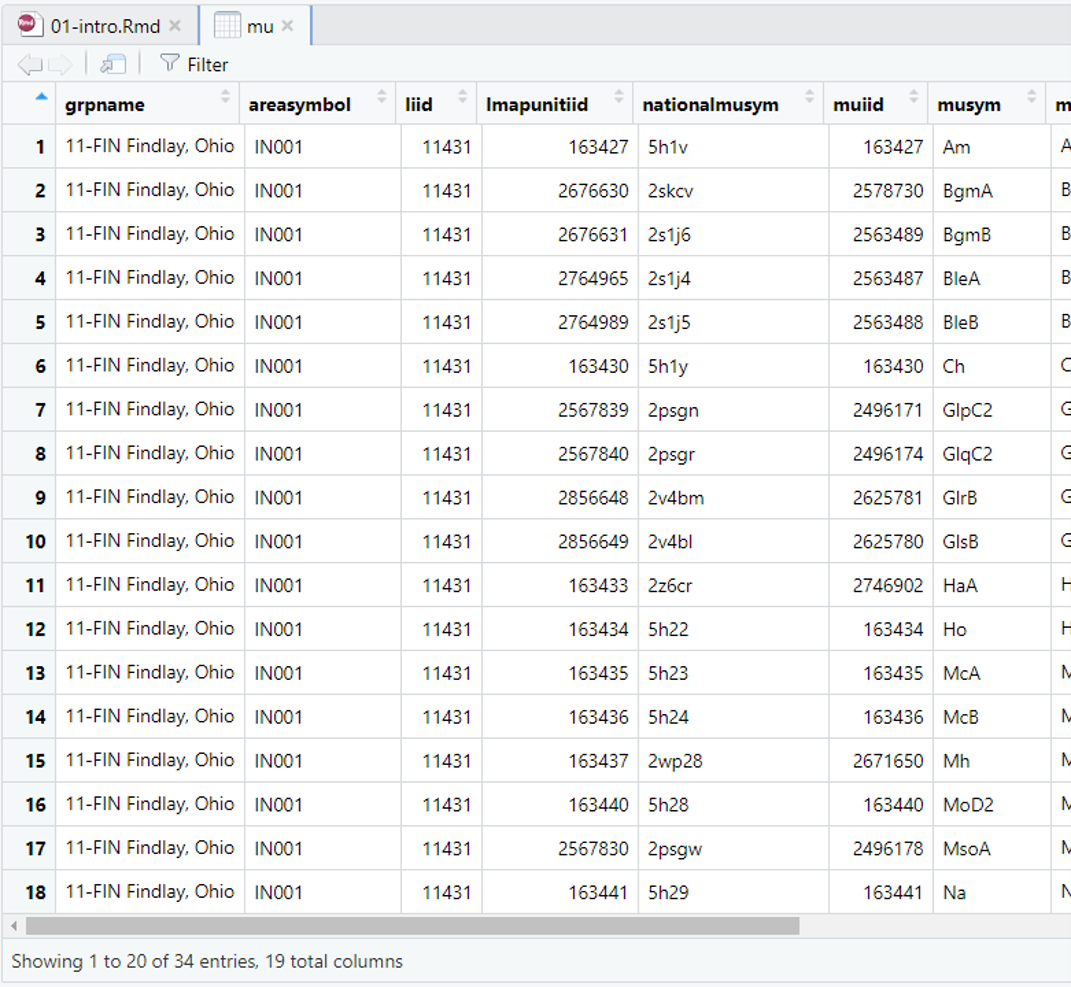
Additionally you can use the following functions to view your data in R.
| Function | Description |
|---|---|
print() |
prints the entire object (avoid with large tables) |
head() |
prints the first 6 lines of your data |
str() |
shows the data structure of an R object |
names() |
lists the column names (i.e., headers) of your data |
ls() |
lists all the R objects in your workspace directory |
dput() |
print code to re-create an R object |
View() |
show a spreadsheet-style data viewer for an R object |
Try entering the following commands to view the mu dataset in R:
A data object is anything you’ve created or imported and assigned a name to in R. The Environment tab allows you to see what data objects are in your R session and expand their structure.
If you wanted to delete all data objects from your R session, you could click the broom icon from the Environments tab. Otherwise you could type:
# Remove all R objects
rm(list = ls(all = TRUE))
# Remove individual objects by name
rm(mu, leg, sand)![]()
1.12.2 Filtering or Subsetting Data
When analyzing data in NASIS, filtering is typically accomplished by loading your selected set with only the records you’re interested in. However, it is often useful or necessary to subset your data after it’s loaded. This can allow you to isolate interesting records within large datasets. For these reasons R has numerous options/functions for filtering data.
Data frames can be subset by both columns and rows, using either names, position (e.g. column 1, row 5), or logical indices (e.g. TRUE and FALSE). Another particularly useful feature is the use of pattern matching which uses regular expressions to select data, which is similar to the LIKE statement from SQL.
**Filtering with names and numerical indices
# Filtering with names (character values)
mu$areasymbol # select column names using $
mu[, c("areasymbol", "musym")] # select column names using []
mu[c("1", "2"), ] # select row names using []
mu[c("1", "2"), c("areasymbol", "musym")] # select column and row names using []
# Filtering by position (integer values)
mu[1, ] # select row 1
mu[, 1] # select column 1
mu[2, 2] # select row 2 and column 2
mu[c(1, 2, 3), ] # select rows 1, 2, 3
mu[-c(1, 2), ] # drop rows 1, 2Logical Vectors and Operators
Logical values encode one of two possible values (TRUE or FALSE) and are interpreted via logical operators. Some of the more common operators are demonstrated in the following figure. Logical operators can be combined using parenthesis to describe complex subsetting criteria.
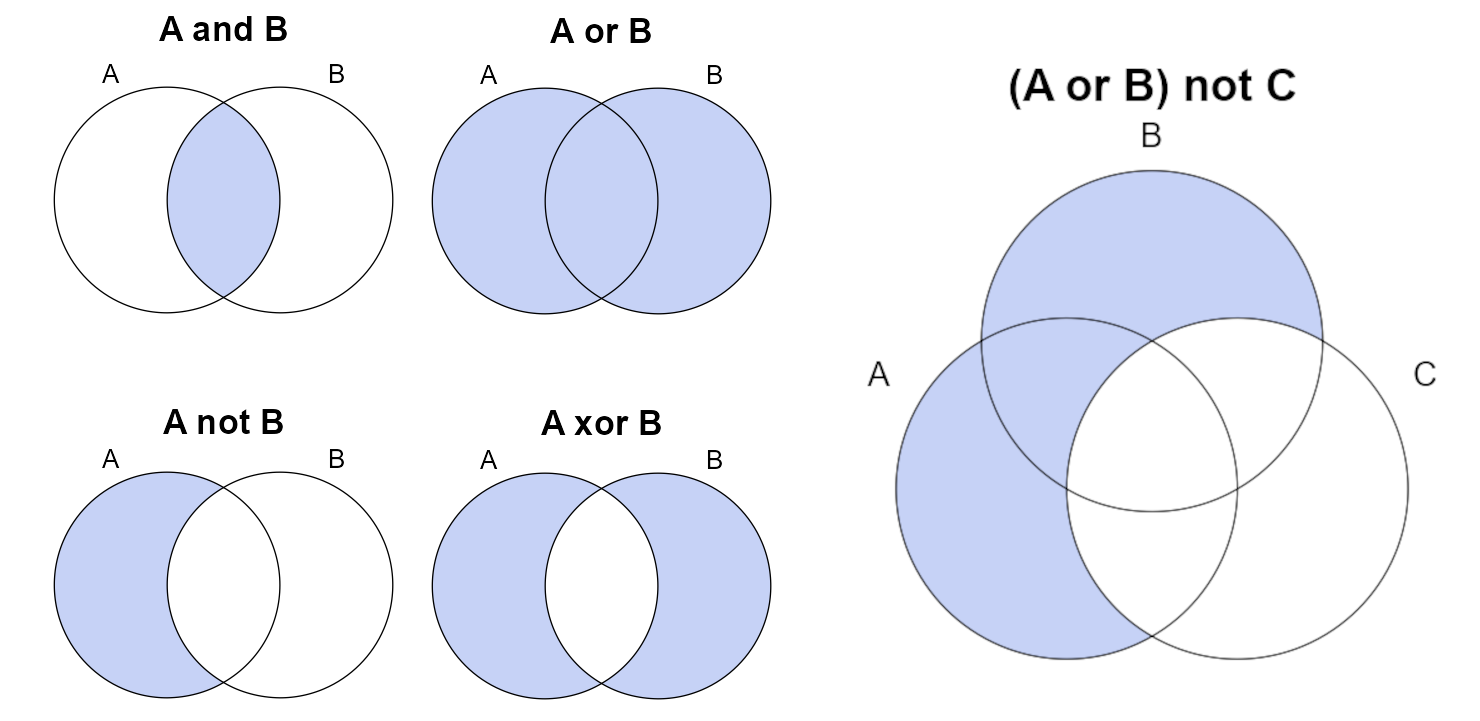
Common operators and functions that return logical vectors:
A == B: “A is equal to B”, note the use of double-equal signA != B: “A is not equal to B”, note that!can be used to invert any logical operator<, >, <=, >=: inequality operatorsgrepl(pattern, x): textpatternfound inx, similar to SQLLIKE(e.g.areasymbol LIKE "CA%"), REGEX Resources in Chapter 2
Vectorized logical operators:
A & B:&is the “AND” operator, “intersection of A and B”A | B:|is the “OR” operator, “union of A and B”xor(A, B): exclusive OR, “A or B, but not both”A %in% B: equivalent to SQLINoperator (e.g.areasymbol IN ("IN001", "IN111"))
See Chapter 2 for a more detailed description.
Filtering with logical vectors
# Standard evaluation with base R [], be careful of NA
# Filtering with logical vectors
mu[mu$areasymbol == "IN001", ] # select rows that equal IN001
mu[mu$areasymbol != "IN001", ] # select rows that do not equal IN001
mu[, names(mu) == "areasymbol"] # select columns that equal areasymbol
mu[, names(mu) %in% c("areasymbol", "musym")] # select columns that match areasymbol and musym
mu[grepl("Miami", mu$muname), ] # select rows that contain Miami
# if there are NA present, be sure to use which()
mu[which(mu$areasymbol == 'IN001'), ]
# Non-standard evaluation with tidyverse
library(dplyr)
# Filtering rows
filter(mu, areasymbol == "IN001")
filter(mu, areasymbol != "IN001")
filter(mu, areasymbol %in% c("IN001", "IN111"))
filter(mu, grepl("Miami", muname))
filter(mu, muacres > 0)1.12.3 Transforming Data
This allows you to create new columns by convert, compute, or combine data within existing columns.
1.12.4 Sorting Data
Sorting allows you to rearrange your data. Beware R has several similar functions (e.g. sort and order) for sorting data only work with specific datatypes. The tidyverse function arrange is designed to work with data frames.
1.12.5 Piping Data
Another particularly useful feature provided by the magrittr package and used in the tidyverse is the use of pipe (%>%). Base R also has a native pipe operator (|>). Using the RStudio keyboard shortcut Ctrl + Shift + M inserts the pipe you have selected as default in Global Options > Code.
f(x,y) becomes x %>% f(y)
The “pipe” is something that occurs in many programming languages and computing contexts. It allows output from one expression to be passed as input to the first argument of the next function. This allows sequences of commands to be read from right to left b(or top to bottom) rather than from the inside out.
# non-piping example 1
mu_sub <- filter(mu, areasymbol == "IN001")
mu_sub <- mutate(mu_sub, pct_100less = pct_component < 100)
# non-piping example 2
mu_sub <- mutate(filter(mu, areasymbol == "IN001"), pct_100less = pct_component < 100)
# piping
mu_sub <- mu %>%
filter(areasymbol == "IN001") %>%
mutate(pct_100less = pct_component < 100)1.12.6 Merging/Joining or Combining Data
Joining
When working with tabular data you often have 2 or more tables you need to join. There are several ways to join tables. Which direction to join and which columns to join will determine how you achieve the join.
# inner join
leg_mu <- inner_join(leg, mu, by = c("liid", "areasymbol"))
# left join
leg_mu <- left_join(leg, mu, by = c("liid"))
# right_join
leg_mu <- right_join(leg, mu, by = "liid")Combining
If your tables have the same structure (e.g. columns), or length and order you may simply combine them. For example, if you have two different mapunit tables.
1.12.7 Aggregating or Grouping Data
Because soil data has multiple dimensions (e.g. properties and depths) and levels of organization (e.g. many to one relationships), it is often necessary to aggregate it. For example, when we wish to make a map we often need to aggregate over components and then map units. Depending on the data type this aggregation may involve taking a weighted average or selecting the dominant condition.
The group_by function defines the groups over which we wish to summarize the data.
1.12.8 Reshaping Data
Typically data is stored in what is known as a wide format, where each column contains a different variable (e.g. depth, clay, sand, rocks). However, sometimes it is necessary to reshape or pivot to a long format, where each variable/column is compressed into 2 new rows. One new column contains the old column names, while another new column contains the values from the old columns. This is particularly useful when combining multiple variables into a single plot.
library(tidyr)
# Simplify mu example dataset
mu2 <- mu %>%
select(grpname, areasymbol, musym, muacres, n_component, pct_hydric) %>%
slice(1:5)
print(mu2)
# Pivot long
mu2_long <- pivot_longer(mu2, cols = c(muacres, n_component, pct_hydric))
print(mu2_long)
# Pivot wide
mu2_wide <- pivot_wider(mu2_long, names_from = name)
print(mu2_wide)Exercise 2: Data Manipulation
Save the code you use in an R script, add answers as comments, and send to your mentor.
Get the NASIS legend table for the state of Wisconsin using the soilDB function
get_legend_from_NASISWebReport(). Set argumentsmlraoffice = "%"andareasymbol = "WI%"Filter the legend table to find rows where
areaacresis less than 200,000. Inspect the result to find theareasymbolvalues.Load the mapunit table using soilDB
get_mapunit_from_NASISWebReport(). Get data for the area symbols you identified in step 2.Calculate the acreage of hydric soils for each mapunit by multiplying
muacresbypct_hydric. Note:pct_hydricis a percentage, not a proportion.Sum the acres of hydric soils within each soil survey area using dplyr functions
group_by()andsummarize().Join the aggregated mapunit table from Step 5 to the legend table from Step 2 using dplyr
left_join().Calculate the proportions of each soil survey area that are hydric soils.
Answer the following questions:
What Wisconsin soil survey areas are less than 200,000 acres?
What proportion of each soil survey area are hydric soils?
Bonus: How does your joined result in Step 6 differ if you replace dplyr
left_join()withinner_join()? Why? What if you join to the unfiltered legend table from Step 1?
1.13 Review
Given what you now know about R, try to answer the following questions:
Can you think of a situation where an existing hypothesis or conventional wisdom was not repeatable?
What are packages?
What is GitHub?
Where can you get help?
What is a data frame?
What are 3 ways you can manipulate a data frame?
1.14 Additional Reading (Introduction)
- Introductory R Books
- Advanced DSM R Books
- Soil Science R Applications
- Soil Sciences and Statistics Review Articles
- Arkley, R., 1976. Statistical Methods in Soil Classification Research. Advances in Agronomy 28:37-70. https://www.sciencedirect.com/science/article/pii/S0065211308605520
- Mausbach, M., and L. Wilding, 1991. Spatial Variability of Soils and Landforms. Soil Science Society of America, Madison. https://dl.sciencesocieties.org/publications/books/tocs/sssaspecialpubl/spatialvariabil
- Wilding, L., Smeck, N., and G. Hall, 1983. Spatial Variability and Pedology. In : L. Widling, N. Smeck, and G. Hall (Eds). Pedogenesis and Soil Taxonomy I. Conceps and Interactions. Elseiver, Amsterdam, pp. 83-116. https://www.sciencedirect.com/science/article/pii/S0166248108705993
1.8.2 Comments
It is a good idea to include comments in your code, so that in the future both yourself and others can understand what you were doing. Each line with a comment starts with
#.In RStudio, you can use
#comments to create an “outline” for your source documents. Multiple#signs increase the depth of the hierarchy. Ending a comment line with four hyphens (----) indicates that text should be included in the outline. The source file outline using comments in regular .R source files is analogous to the Markdown syntax used in R Markdown and Quarto for headers.For example, the following code block creates two outline sections, each with a nested subsection.
To show the outline view, click the “outline” button in the top-right hand corner of the source window. Paste it in a fresh R document to try it out.