Rosetta is a neural network-based model for predicting unsaturated soil hydraulic parameters from basic soil characterization data. The model predicts parameters for the van Genuchten unsaturated soil hydraulic properties model, using sand, silt, and clay, bulk density and water content.
{rosettaPTF} uses {reticulate} to wrap the Python rosetta-soil module: providing several versions of the Rosetta pedotransfer functions in an R environment.
This package is primarily intended for more demanding use cases (such as calling Rosetta “continuously” on each cell in a stack of rasters), or for accessing the uncertainty and shape metrics from Zhang & Schaap (2017). High-throughput input to the pedotransfer function is possible by using RasterStack (raster) or SpatRaster (terra) objects as input.
Install {rosettaPTF}
First, install the package from GitHub:
if (!require("remotes")) install.packages("remotes")
remotes::install_github("ncss-tech/rosettaPTF")Then load the rosetta-soil module by loading the R package. If you do not have an available python installation or rosetta-soil module you will be notified.
rosetta-soil Python module
The rosetta-soil module is a Python package maintained by Dr. Todd Skaggs (USDA-ARS) and other U.S. Department of Agriculture employees.
The Rosetta pedotransfer function predicts seven parameters (five in versions < 0.2.0) for the van Genuchten model of unsaturated soil hydraulic properties:
-
theta_r: residual volumetric water content -
theta_s: saturated volumetric water content -
alpha: retention shape parameter[1/cm]. Logarithmic (log10) scale ifestimate_type="log"(default); Geometric mean ifestimate_type="geo". -
npar: retention shape parameter (also referred to asn). Logarithmic (log10) scale ifestimate_type="log"(default); Geometric mean ifestimate_type="geo". -
ksat: saturated hydraulic conductivity[cm/d]. Logarithmic (log10) scale ifestimate_type="log"(default); Geometric mean ifestimate_type="geo". -
K0: unsaturated hydraulic conductivity matching point[cm/d]. Logarithmic (log10) scale ifestimate_type="log"(default); Geometric mean ifestimate_type="geo". -
lpar: unsaturated hydraulic conductivity exponent.
For each set of input data a mean and standard deviation of each parameter is given.
Less demanding use cases are encouraged to use the web interface or API endpoint. There are additional wrappers of the API endpoints provided by the soilDB R package ROSETTA() method. For small amounts of data consider using the interactive version that has copy/paste functionality: https://www.handbook60.org/rosetta.
Input Data
The Rosetta model relies on a minimum of 3 soil properties, with increasing (expected) accuracy as additional properties are included:
- Required,
sand,silt,clay: USDA soil texture separates (percentages) that sum to 100% - Optional,
bulk density (any moisture basis): mass per volume after accounting for >2mm fragments, units of grams/cm3 - Optional,
volumetric water content at 33 kPa: roughly “field capacity” for most soils, units of cm3/cm3 - Optional,
volumetric water content at 1500 kPa: roughly “permanent wilting point” for most plants, units of cm3/cm3
The default order of inputs is: sand, silt, clay, bulk density (any basis), water content (field capacity; 33 kPa), water content (permanent wilting point; 1500 kPa) of which the first three are required.
If you specify field capacity water content, you must specify bulk density. If you specify permanent wilting point water content you must also specify bulk density and field capacity water content.
{reticulate} Setup
If you are using this package for the first time you will need to have Python installed and you will need to download the necessary modules.
You can set up {reticulate} to install modules into a virtual environment. {reticulate} offers reticulate::install_python() to download and set up Python if you have not yet done so.
For example, install a recent version of Python, and create a virtual environment called "r-reticulate"
# download latest python 3.10.x
reticulate::install_python(version = "3.10:latest")
reticulate::virtualenv_create("r-reticulate")Finding the python binaries
rosettaPTF::find_python()
#>[1] "D:/workspace/rosettaPTF/.venv/Scripts/python.exe"find_python() provides heuristics for setting up {reticulate} to use Python in commonly installed locations.
The first attempt makes use of Sys.which() to find installations available in the user path directory.
If automatic configuration via find_python() fails (returns NULL) you can manually set a path to the python executable with the {reticulate} RETICULATE_PYTHON environment variable: Sys.setenv(RETICULATE_PYTHON = "path/to/python") or reticulate::use_python("path/to/python")
Install rosetta-soil Python Module
The {rosettaPTF} install_rosetta() method wraps reticulate::py_install("rosetta-soil"). You may not need to install the rosetta-soil module if your environment is set up, as {reticulate} will install/upgrade dependencies of packages as specified in the package configuration section of the DESCRIPTION file.
You can use install_rosetta() to install into custom environments by specifying envname as needed. After installing a new version of the module you should restart your R session.
rosettaPTF::install_rosetta()
#>+ "D:/workspace/rosettaPTF/.venv/Scripts/python.exe" -m pip install --upgrade --no-user NA --upgrade rosetta-soil
#>Using virtual environment "D:/workspace/rosettaPTF/.venv" ...
#>[1] TRUEAlternately, to install the module manually with pip you can run the following command. This assumes a Python 3 binary called python can be found on your path.
High-Throughput Processing
rosettaPTF supports efficient batch processing of large soil datasets through vectorized computation in the underlying rosetta-soil backend.
For large datasets:
- Use
cores > 1withrun_rosetta()andSpatRasterorRaster*inputs to parallelize the calls.
run_rosetta()
Batch runs of Rosetta models can be done using list, data.frame, matrix, RasterStack, RasterBrick and SpatRaster objects as input.
Plain R lists are the preferred input format. The helper SoilDataFromArray() is deprecated.
list() Input Example
# Plain R lists are passed directly to Python
run_rosetta(list(c(30, 30, 40, 1.5), c(55, 25, 20), c(55, 25, 20, 1.1)),
rosetta_version = 3)| id | model_code | theta_r_mean | theta_s_mean | log10_alpha_mean | log10_npar_mean | log10_Ksat_mean | log10_K0_mean | lpar_mean | theta_r_sd | theta_s_sd | log10_alpha_sd | log10_npar_sd | log10_Ksat_sd | log10_K0_sd | lpar_sd |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 0.115 | 0.418 | -2.067 | 0.112 | 0.833 | 0.023 | -1.035 | 0.013 | 0.009 | 0.083 | 0.013 | 0.092 | 0.232 | 1.588 |
| 2 | 2 | 0.086 | 0.389 | -1.898 | 0.135 | 1.186 | 0.420 | -0.953 | 0.006 | 0.006 | 0.075 | 0.012 | 0.084 | 0.228 | 1.099 |
| 3 | 3 | 0.091 | 0.485 | -2.022 | 0.151 | 1.906 | 0.373 | -0.325 | 0.013 | 0.013 | 0.100 | 0.018 | 0.142 | 0.254 | 1.244 |
Output model_code reflects the number of parameters in the input.
Parameter Estimation Scales
By default, rosettaPTF uses estimate_type = "log" to maintain backward compatibility with previous versions, returning alpha, npar, and Ksat on a logarithmic (log10) scale. You can now request estimates on a linear scale directly:
run_rosetta(list(c(30, 30, 40, 1.5)), estimate_type = "arith")| id | model_code | theta_r_mean | theta_s_mean | alpha_mean | npar_mean | ksat_mean | k0_mean | lpar_mean | theta_r_sd | theta_s_sd | alpha_sd | npar_sd | ksat_sd | k0_sd | lpar_sd |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 0.115 | 0.418 | 0.009 | 1.295 | 6.954 | 1.25 | -1.049 | 0.013 | 0.009 | 0.002 | 0.039 | 1.47 | 0.786 | 1.577 |
Note that the output column names will change to reflect the linear scale (e.g., ksat_mean instead of log10_Ksat_mean).
Additionally, estimate_type = "geo" can be used to return the geometric mean of the bootstrap estimates. This is often preferred for parameters like and which can span several orders of magnitude, as the geometric mean is less sensitive to extreme outliers in the bootstrap ensemble than the arithmetic mean. Mathematically, the geometric mean is equivalent to the exponent of the mean of the log-transformed values.
run_rosetta(list(c(30, 30, 40, 1.5)), estimate_type = "geo")| id | model_code | theta_r_mean | theta_s_mean | alpha_mean | npar_mean | ksat_mean | k0_mean | lpar_mean | theta_r_sd | theta_s_sd | alpha_sd | npar_sd | ksat_sd | k0_sd | lpar_sd |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3 | 0.115 | 0.418 | 0.009 | 1.294 | 6.8 | 1.055 | -1.035 | 0.013 | 0.009 | 0.002 | 0.039 | 1.47 | 0.767 | 1.588 |
The data.frame interface allows for using using custom column names and order. If the vars argument is not specified it is assumed that the columns are in the order specified in the run_rosetta() manual page.
run_rosetta(data.frame(
d = c(NA, 1.5),
b = 60,
a = 20,
c = 20
), vars = letters[1:4])| id | model_code | theta_r_mean | theta_s_mean | log10_alpha_mean | log10_npar_mean | log10_Ksat_mean | log10_K0_mean | lpar_mean | theta_r_sd | theta_s_sd | log10_alpha_sd | log10_npar_sd | log10_Ksat_sd | log10_K0_sd | lpar_sd |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 0.090 | 0.430 | -2.426 | 0.176 | 1.193 | -0.109 | 0.181 | 0.007 | 0.009 | 0.074 | 0.013 | 0.087 | 0.219 | 1.623 |
| 2 | 3 | 0.085 | 0.389 | -2.319 | 0.160 | 0.996 | -0.037 | -0.121 | 0.010 | 0.008 | 0.080 | 0.018 | 0.078 | 0.206 | 1.363 |
Soil Data Access / SSURGO Mapunit Aggregate Input Example
This example pulls mapunit/component data from Soil Data Access (SDA). We use the {soilDB} function get_SDA_property() to obtain representative values for sand, silt, clay, and bulk density (1/3 bar) we run Rosetta on the resulting data.frame (one row per mapunit) then use raster attribute table (RAT) to display the results (1:1 with mukey).
library(soilDB)
library(terra)
library(rosettaPTF)
# obtain mukey map from SoilWeb Web Coverage Service (800m resolution SSURGO derived)
res <- mukey.wcs(aoi = list(aoi = c(-114.16, 47.65,-114.08, 47.68), crs = 'EPSG:4326'))
#>Loading required namespace: sf
#>
# request input data from SDA
varnames <- c("sandtotal_r", "silttotal_r", "claytotal_r", "dbthirdbar_r")
resprop <- get_SDA_property(property = varnames,
method = "Dominant Component (numeric)",
mukeys = unique(values(res$mukey)))
#>single result set, returning a data.frame
# keep only those where we have a complete set of 4 parameters (sand, silt, clay, bulk density; model code #3)
soildata <- resprop[complete.cases(resprop), c("mukey", varnames)]
# run Rosetta on the mapunit-level aggregate data
system.time(resrose <- run_rosetta(soildata[,varnames]))
#> user system elapsed
#> 0.00 0.00 0.03
# transfer mukey to result
resprop$mukey <- as.numeric(resprop$mukey)
resrose$mukey <- as.numeric(soildata$mukey)
# merge property (input) and rosetta parameters (output) into RAT
levels(res) <- merge(cats(res)[[1]], resprop, by.x = "ID", by.y = "mukey", all.x = TRUE, sort = FALSE)
levels(res) <- merge(cats(res)[[1]], resrose, by.x = "ID", by.y = "mukey", all.x = TRUE, sort = FALSE)
# convert categories based on mukey to numeric values
res2 <- catalyze(res)
# make a plot of the predicted Ksat
plot(res2, "log10_Ksat_mean")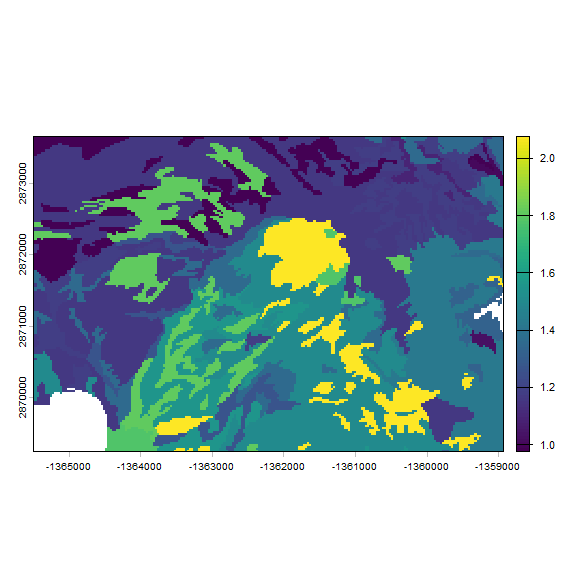
SpatRaster (terra) Input Example
The above example shows how to create raster output based on discrete (SSURGO polygon derived) data. A more general case is when each raster cell has “unique” values (i.e. continuous raster inputs). run_rosetta() has an S3 method defined for SpatRaster input.
We previously merged the input data from SDA (an ordinary data.frame) into the RAT of res; exploiting the linkage between mukey and raster cells to make the map. For comparison with the mukey results above we stack de-ratified input layers and create a new SpatRaster.
res3 <- rast(list(
res2[["sandtotal_r"]],
res2[["silttotal_r"]],
res2[["claytotal_r"]],
res2[["dbthirdbar_r"]]
))
# SpatRaster to data.frame interface (one call on all cells)
system.time(test2 <- run_rosetta(res3))
#> user system elapsed
#> 3.10 3.88 17.37
# make a plot of the predicted Ksat (identical to mukey-based results)
plot(test2, "log10_Ksat_mean")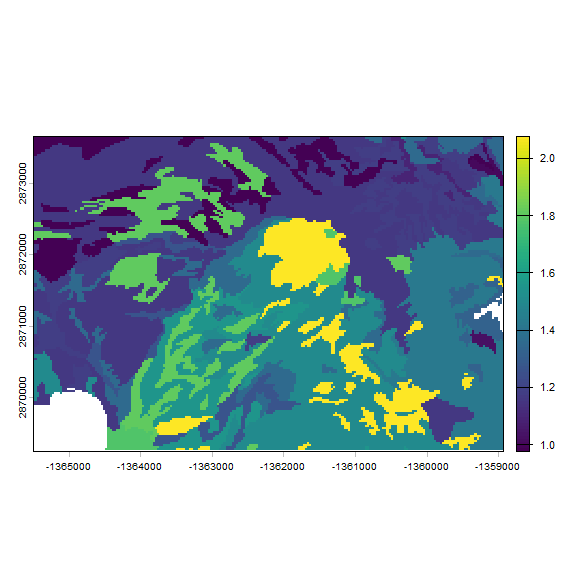
You will notice the results for Ksat distribution are identical since the same input values were used, but the latter approach took longer to run. The time difference is the difference of estimating ~40 (1 estimate per mapunit key) versus ~30,000 (1 estimate per raster cell) sets of Rosetta parameters.
Extended Output with Rosetta S3 Class
Make a Rosetta class instance for running extended output methods
Note that each instance of Rosetta has a fixed version and model code, so if you have heterogeneous input you need to iterate over model code.
# defaults are version 3 and model code 3 (4 parameters: sand, silt, clay and bulk density)
my_rosetta <- Rosetta(rosetta_version = 3, model_code = 3)
predict() Rosetta Parameter Values and Standard Deviations from a Rosetta instance
predict(my_rosetta, list(c(30, 30, 40, 1.5), c(55, 25, 20, 1.1)))
#>$mean
#> [,1] [,2] [,3] [,4] [,5]
#>[1,] 0.11535773 0.417912 -2.067139 0.1120102 0.8325407
#>[2,] 0.09130753 0.485032 -2.022388 0.1510716 1.9060148
#>
#>$stdev
#> [,1] [,2] [,3] [,4] [,5]
#>[1,] 0.01335011 0.009377977 0.08251142 0.01323413 0.09245277
#>[2,] 0.01277141 0.013062171 0.10020312 0.01763982 0.14163567
#>Extended Rosetta Predictions, Parameter Distributions and Summary Statistics after Zhang & Schaap (2017) with ann_predict()
ann_predict() is deprecated and redirects to predict(), as the underlying bootstrap data is now returned by predict() and summarized by R.
ann_predict(my_rosetta, list(c(30, 30, 40, 1.5), c(55, 25, 20, 1.1)))
#>ann_predict() is deprecated in rosetta-soil >= 0.3.0. Use predict() instead.
#>$mean
#> [,1] [,2] [,3] [,4] [,5]
#>[1,] 0.11535773 0.417912 -2.067139 0.1120102 0.8325407
#>[2,] 0.09130753 0.485032 -2.022388 0.1510716 1.9060148
#>
#>$stdev
#> [,1] [,2] [,3] [,4] [,5]
#>[1,] 0.01335011 0.009377977 0.08251142 0.01323413 0.09245277
#>[2,] 0.01277141 0.013062171 0.10020312 0.01763982 0.14163567
#>New Features in rosetta-soil 0.3.0
rosesoil()
rosesoil() is a new R wrapper for the upstream rosesoil() function, which returns a structured result including all model metadata.
| sand | silt | clay | rhob | th33 | th1500 | version | estimate_type | code | thr | ths | alpha | npar | ksat | k0 | lpar | thr_std | ths_std | alpha_std | npar_std | ksat_std | k0_std | lpar_std |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 33 | 33 | 34 | 1.5 | 3 | arith | 3 | 0.108 | 0.406 | 0.008 | 1.32 | 7.141 | 1.281 | -0.861 | 0.012 | 0.008 | 0.001 | 0.038 | 1.416 | 0.764 | 1.481 |
UnsaturatedK()
UnsaturatedK provides a way to predict unsaturated hydraulic conductivity parameters K0 and lpar from retention parameters.
uk <- UnsaturatedK()
predict(uk, list(c(0.12, 0.42, 0.008, 1.29)))| log10_K0_mean | lpar_mean | log10_K0_sd | lpar_sd |
|---|---|---|---|
| -0.041 | -1.033 | 0.231 | 1.662 |
Selected References
Three versions of the ROSETTA model are available, selected using rosetta_version argument:
-
rosetta_version1: Schaap, M.G., F.J. Leij, and M.Th. van Genuchten. 2001. ROSETTA: a computer program for estimating soil hydraulic parameters with hierarchical pedotransfer functions. Journal of Hydrology 251(3-4): 163-176. doi: 10.1016/S0022-1694(01)00466-8. -
rosetta_version2: Schaap, M.G., A. Nemes, and M.T. van Genuchten. 2004. Comparison of Models for Indirect Estimation of Water Retention and Available Water in Surface Soils. Vadose Zone Journal 3(4): 1455-1463. doi: 10.2136/vzj2004.1455. -
rosetta_version3: Zhang, Y., and M.G. Schaap. 2017. Weighted recalibration of the Rosetta pedotransfer model with improved estimates of hydraulic parameter distributions and summary statistics (Rosetta3). Journal of Hydrology 547: 39-53. doi: 10.1016/j.jhydrol.2017.01.004. Version 3 includes predictions for unsaturated conductivity parametersK0andlpar.